本文共字,预计阅读时间。
Capital One 的风控系统是怎么搭建的?所谓大数据驱动的“测试与学习”,是如何做到的?如何建立大数据风控体系?
小赢科技总裁成少勇在一本财经学院主办的“Capital One基因密钥”闭门训练营中,为大家剖析Capital One模式背后的密钥。以下是他分享的部分干货。
01 风控体系
Capital One不到20多年时间从一个小银行信用卡部门做到美国前几名的银行的关键原因是他的文化和管理体制。
我们在实际利用的时候,不会照搬Capital One原来数据和模型方法,因为时代不一样了,技术进步了,而且中国的数据和国外不一样。
所以我讲的是Capital One成功的原理和本质,然后需要结合实际去理解,落实。
首先讲风控系统,大数据风控的核心是风控基础设施。这里包括了系统,数据,数据分析和模型,但最终能成为核心竞争力的还是人才和管理体制。

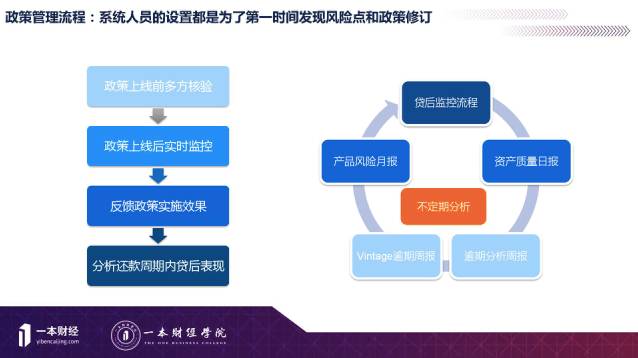
具体我讲一下政策管理流程,我们在上线之前要做多方面的工作,首先我要评估一下,调整政策会进来多少客户,对收入和风险(逾期)的影响有多大;上线时要实时监控,业务变化是否符合我们的假设和预期;一段时间很快就要评估政策对业务量的影响;等风险表现出现后在评估对收入和损失的影响是否符合预期。这样的政策调整是频繁的,要大量的跟踪和数据分析。
衡量风险最好的曲线是vintage analysis, 一段时间放款的贷款整体上在生命周期的风险表现,这个风险曲线也是风险管理很重要、很根本的东西。短期现金贷虽然时间短,一般在一个月以内,但是也可以从客户的生命周期来看其长期风险。
经过大量实际数据的建模分析,实际发生的风险是时间,客群内在风险水平和外部环境三个因素共同决定的,可以用数学的方法计算出来。
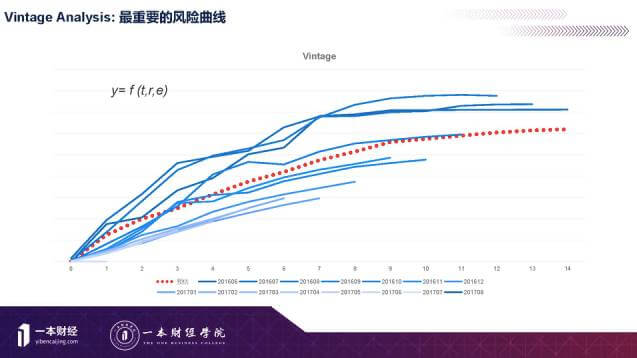
T代表时间,图中是12期的分析曲线。
R是风险,存在各种衡量方法。
E是外部因素。比如经济状况、催收情况,市场情况,自然灾害等。
通过这个曲线图,你就明白目前资产处于什么风险水平,如果外部环境变化会处于什么风险水平。
02 模型
从方法论上说,传统金融机构根据经验,利用学历、性别等进行风险识别。
移动互联网时代,新的数据分析方向,申请过程中,将对用户设备及行为数据进行采集,包括:IP、设备指纹、移动网上行为、社交数据,电商行为等。比如对于存在问题的设备、IP等,将关联相关申请进行集中防范。
数据复杂,数据量很大以后,就需要做模型了。成熟的模型,加上丰富的数据,对以数据为导向的政策至关重要。
目前在中国零售风险管理采用的模型主要有两种形式:逻辑回归和机器学习模型。
逻辑回归模型技术成熟,在中美的零售风险管理中长期使用。但在互联网大数据时代有一定的局限性。机器学习模型在互联网大数据时代能弥补逻辑回归模型的不足,在目前中国的科技金融企业中得到了广泛的应用。


03 测试学习
说完风控系统,然后咱们再谈谈具体的应用。

在测试流程这套体系下,一切就水到渠成了。
比如一个比较好的客群,我们可以通过提额增加公司的净利润,但不知道提额多少合适。把客群分成4等分,分别给以10%,20%,30%,40%的提额,再跟踪业务量,收入的变化和风险损失的变化,盈利最高的选择在测试中可以发现答案。

测试对公司是有成本的你要有很好的数据能力。没有数据分析师你这一块就做不好,没有好的系统能力做得太少也不行。
测试是有很大成本的,比如损失,人力成本、时间成本等。需要优秀的分析师来设计解决关键问题的测试方案, 并且进行跟踪数据分析。 测试还要有灵活强大的系统, 能快速实施大量的测试。在Capital One早期,每年的测试都数以万计。

再次强调一下,大数据风控的核心是风控基础设施,这里包括了系统,数据,数据分析和模型,但最终能成为核心竞争力的还是人才和管理体制。
(整理 | 洛桑)
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号