本文共字,预计阅读时间。
由于比特币采用基于公钥的钱包地址作为用户在区块链网络上的身份,且钱包地址由用户自由生成,与用户身份特征无关,因此比特币的匿名性导致人们很难推测用户的真实身份信息。
目前为止,有许多尝试推测比特币地址身份的方法,其中最常用的推测方法是基于多输入交易地址和挖矿交易地址,通过递归算法的进行的判断,准确率几乎可以达到100%,是非常有效的追寻比特币地址拥有者的方法。
但是随着比特币在全球范围内的普及,目前比特币的整个区块已非常庞大(截止2018年8月28日,区块高度为538862,大小接近180G),如果使用该方法所依靠的递归算法对整个区块链上的地址进行计算,需要消耗大量计算资源和时间,限制了对该方法的使用范围;另外这种方法只能通过设置一定条件追踪部分满足条件的比特币地址拥有者,而无法涵盖所有比特币地址。
火币研究院在该算法的研究成果上,通过从比特币区块链中提取特征分析不同账户的链上转账信息,使用随机森林(Random Forest)的机器学习算法对地址类别进行归类。该机器学习算法并非替代原有的聚类算法,而是对原有的聚类方法应用范围的补充。牺牲一小部分的准确性,以适用于更广泛的比特币区块链转账研究。
本文主要分为两个部分:第一部分 1)简述比特币交易系统及交易过程 2)基于多输入交易地址以及挖矿交易地址的分类方法 3)通过随机森林算法建模对地址类别进行归类方法 4)两种算法的比较。第二部分利用模型进行实例分析。目的是为读者提供将比特币地址拥有者进行分类的思路,以便在不同的应用场景下,选择更为高效的方法对比特币区块链数据进行多维度分析。
文章的第二部分,我们通过分析2018年8月8日至8月15日所有的比特币地址与转账记录,基于分类算法得出活跃地址数的分布:
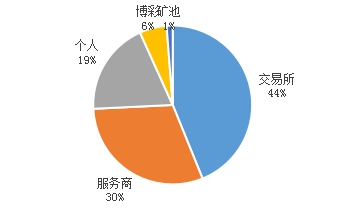
活跃地址中,44%为交易所地址,30%为服务商地址,19%为个人钱包地址,6%为博彩公司,1%为矿池。
再进一步分析新建地址数和转账明细得出:
1) 交易所和服务商新增地址数在这几周内变化不大,但是新建个人钱包地址数却呈现明显下降趋势。
2) 比特币由个人地址转入交易所的量远远大于从交易所转入个人地址的量。
最后推测该周比特币价格大幅下挫原因可能有:
1) 新入场的投资者人数的减少。
2) 很有可能是有大量用户将个人钱包中的比特币转入交易所进行抛售。
第一部分 模型简介
1.比特币的交易过程和特点
比特币交易有三个特点:1)所有交易记录大众可见,2)一笔交易可以有多个输入(inputs)和多个输出(outputs) 3)每笔交易都通过公钥-私钥对来识别交易的付款人和收款人。
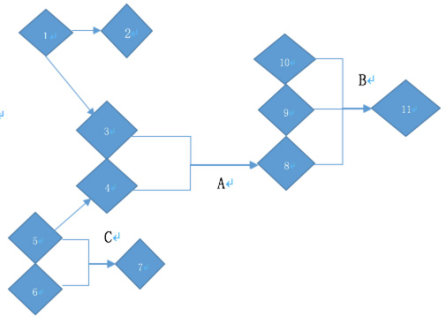
图1为真实出现在比特币网络的交易流,每个顶点代表一个比特币地址,顶点之间的连线和箭头代表一笔交易。正如以上提到的比特币的第二个特点,一笔交易可以有多个输入(图中交易A,B,C),基于多输入交易地址以及挖矿交易地址的归类方法正是使用了这个特点。
图1.比特币交易用户地址网络
2.基于多输入交易地址和挖矿地址的归类(算法1)
2.1多输入交易地址
通过Fergal Reid,MAO H L,MAN H 等人的研究[1][2][3],得出结论:当用户支付额度超过了用户钱包中每一个可用地址中比特币的数量时,为了避免执行多笔交易完成支付造成交易费用方面的损失,用户会从钱包中选择多个比特币地址聚合在一起进行匹配支付,实现多输入交易。而又由于比特币交易中使用每一个地址中的资金都需要单独签名,所以我们可以反过来认为一个多输入交易中的所有输入地址来源于同一个用户。(准确率可以近似达到100%)
因此我们可以认为图1中,3与4为同一用户,同理:8,9与10,以及5与6 都为同一用户。
2.2挖矿交易地址
同样,对于没有输入地址的交易(也就是俗称的挖矿交易),由于挖矿的本质是在一台服务器上运行比特币挖矿程序,可以认为一个产量交易中的输出地址是由同一个用户进行配置。所以如果一个或多个地址是同一个挖矿交易的输出,可以认为它们被同一个用户控制。
对于用户自行挖矿模式的情况,挖矿交易地址聚类的准确率可达100%。对于“矿池”模式,多数情况下,出块奖励会在产量交易中转入“矿主”的私有收益地址,然后根据矿池用户的算力贡献进行二次收益分配,因此同样可以认为产量交易输出地址属于同一用户。
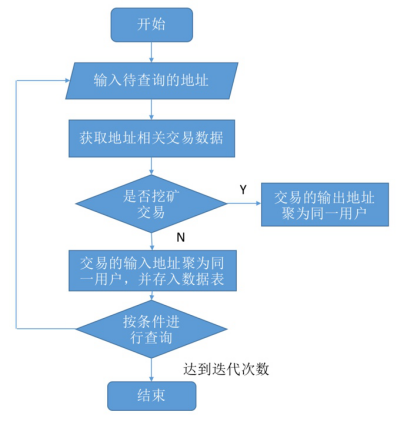
2.3归类流程
归类算法的框架如图2所示,迭代的次数越多,查到的地址数就会越多,全面性就越好,但是迭代次数的增多同时也会降低聚类效率。
图2. 基于多输入交易地址和挖矿地址的归类流程
以上,我们描述了基于多输入交易地址和挖矿地址的归类模型及其实现方法,该模型可以非常准确地对同一用户的地址进行聚类,且随着迭代次数的增多,得到的同一用户地址数量非常可观:例如,如果我们知道某交易所一些热钱包地址,通过该算法可以得出大量的这个交易所其他的热钱包地址,且准确率近似100%。
然而该算法缺点是有一定的局限性:我们无法了解比特币网络的所有地址的拥有者,对于一个不在数据表的地址,我们无法对其进行归类。
火币研究院在研究了该算法的基础上,通过从比特币区块链中提取不同类别比特币地址的特征,建立地址归类模型,能够对更为广泛的匿名比特币地址进行归类。
3.基于随机森林的比特币地址分类(算法2)
3.1 标记类别和样本选取
我们为建模随机抽样选取了8045条样本,并分为五个类别标记:交易所(1591),矿池(1684),服务商(1669),博彩公司(1601),个人(1500)。
建模所用的地址标签信息主要来自于WalletExplorer,该网站已经通过以上方法,分类了数万个地址,有五个不同的类别(交易所,矿池,服务商,博彩公司,旧地址),其中旧地址类别现已很少有交易记录,我们将此类别删除。其余四个类别为了保持每个标签数据的数量维持在同一水平,以免出现数据不平衡情况,我们采用了随机抽样的方法,将每个分类的样本数保持在1500左右。
除了以上四个类别外,我们还加入了“个人”比特币地址这一分类,数据来源于blockchain.info上已标记的个人地址,随机抽取1500个。
3.2 特征选择
通过经验判断和反复观察和实验,我们选取以下地址的特征作为建模的特征:
1) 该地址作为input的交易数量(总转出笔数)
2) 该地址作为output的交易数量(总转入笔数)
3) 该地址作为input的BTC总量(总转出BTC)
4) 该地址作为output的BTC总量(总转入BTC)
5) 该作为Input时,每笔交易Input总数平均数
6) 该作为Output时,每笔交易Input总数平均数
7) 转入笔数/转出笔数 比例
8) (转入笔数-转出笔数)/(转入笔数+转出笔数)
9) 平均每笔转入BTC数量
10) 平均每笔转出BTC数量
11) 是否有过一次或以上的挖矿交易(Coinbase)
12) 该地址作为Input的总矿工费(转出总交易手续费)
13) 该地址作为Output的总矿工费(转入总交易手续费)
14) 转出平均每笔交易费
15) 转入平均每笔交易费
16) 平均每天转出笔数
17) 平均每天转入笔数
以上链上数据火币研究院通过BlockSCI[4]工具,在服务器上搭建BTC节点后,使用Jupyter notebook进行抓取。
3.3 模型选择
在监督学习的模型选择上,通过比较与测试,我们最终选择Random Forest(随机森林)[5]作为我们此次搭建的模型。
该模型主要有以下四个优点:
1) 在当前所有算法中,具有极好的准确率。
2) 能够处理具有高维特征的输入样本,而且不需要降维。(我们的数据一共有17个维度的特征)
3) 适用于多分类问题(5个不同的分类)。
4) 对于缺省值问题也能够获得很好的结果(有些地址只有转入没有转出记录,无法计算出转出相关的数据)。
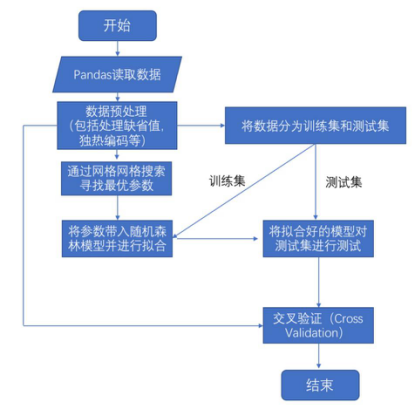
3.4 建模过程
建模过程如图3所示。其中网格搜索的参数主要为:
1) 随机森林中的树的数量(n_estimators)
2) 树的深度最大值(Max_depth)
3) 拆分内部节点所需的最小样本数(Min_samples_split)
4) 叶子节点所需的最小样本数(Min_samples_leaf)
图3:比特币地址分类建模过程
方案使通过Python3 语言实现,使用了Scikit-learn中的RandomForestClassifier(随机森林分类),GridSearchCV(网格搜索),train_test_split(分离测试集和训练集),confusion_matrix(混淆矩阵),K-Fold(K折)等API模块。
训练集和测试集按照2:1的比例进行分割。
3.5 模型得分
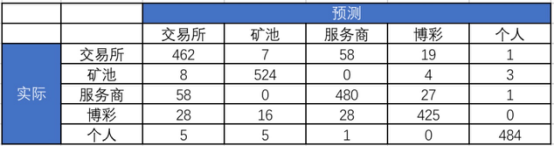
最后经过调试,模型在最终测试集上准确度为90%。
混淆矩阵如图4,除去交易所和服务商的预测混淆的相对较多,整体效果还是较为理想的。
图4:模型得分-混淆矩阵
4. 两种方法对比
火币研究院的比特币分类算法(算法2)并非替代多输入交易地址和挖矿地址分类算法(算法1),而使用算法1运行结果作为地址的标签,在算法1的基础上对其应用范围进行补充。通过牺牲一小部分的准确性,提高其普适性以应用于更宏观的链上数据分析。
两者的区别主要有:
4.1 算法类型不同:
算法1是已知标签地址的情况下,通过多次迭代找寻同时出现在同一个转账中input的地址过程,目的是发现和已知标签地址同属于同一用户的地址,本质上属于一种递归算法,迭代次数越多,获得的具有标记的地址数越多。
而算法2属于机器学习中的监督学习算法,首先将大量带有标记的数据来训练产生一个具有推断功能分类器。有了这个分类器以后,可以根据任何新的个体的特征对该个体进行分类。
4.2 标签来源不同:
算法1和算法2都是从比特币区块链中提取数据,但标签的来源有所不同:
算法1的标签来源可以通过实际观察。例如,如果要获取某交易所的热钱包地址,可以实际在交易所进行充提币交易,交易所充币和提币地址即该交易所的钱包地址;而算法2由于需求的标签数量巨大(至少几千个地址),所以直接引用算法1的结果,比如有些网站如WalletExplorer可直接提供所需标签。
4.3 应用场景不同:
算法1的优点有:
1) 准确率非常高(接近100%)
2) 有具体标签(具体到火币热钱包,OKEX热钱包等)
3) 可解释性强
缺点有:
1) 普适性差(无法为所有地址打上标签)
2) 递归算法所消耗大量计算资源
该算法适用于追踪某个人(黑客,比特币盗窃者),或者某团体(交易所,服务商)的比特币流向。
同样的,算法2的优点有:
1) 普适性强(给定任意一个地址及其链上特征,可以推测该地址的类别)
2) 除了建模需要消耗一定计算资源,在归类时消耗非常少量计算资源。
缺点有:
1) 准确率无法和算法1相比(目前只能达到90%)。
2) 无具体标签(只能归类成五个类别,无法具体到某个交易所或者机构)。
3) 标签可能会随着行为发生变化(可能一个地址最开始被标签为个人地址,但可能未来会更改成交易所地址)
4) 可解释性差(随机森林是个黑盒子)。
该算法适用于对数据准确度要求略低的宏观的链上数据分析(例如目前所有比特币约中有百分之多少在交易所,百分之多少在个人钱包等),以及根据一个地址,迅速判断该地址类别(例如某日比特币链上发生大额转账进入某地址,根据归类算法可以推测该地址属于什么类别)
实际分析中,关于算法2如何提高准确率的问题,我们的解决方法是:将算法2与算法1相结合,在算力条件充足的情况下,使用算法1对尽量多的地址进行归类,(特别是对有大量持币或者大量转账的地址,无法聚类再网上搜寻标签)。将剩余的无法归类的地址再使用算法2进行分类。可以有效地提高数据准确性。
第二部分 实际案例
1. 活跃地址聚类
我们选取2018年8月8日至8月15日的所有的比特币地址与转账记录进行分析。首先对该周出现在input和output的所有地址先使用算法1对已知地址进行聚类,再使用算法2对剩余的地址进行了分类。
该周的活跃地址数共332万个,根据算法的推测,其中143万个为交易所地址,99万个为服务商地址,62万个为个人地址,博彩公司18万,矿池4万。分布如图5所示。其中交易所,服务商和个人钱包地址占了总地址数的93%。
图5 2018年8月8日至8月15日活跃地址分布
2. 新增地址数分解
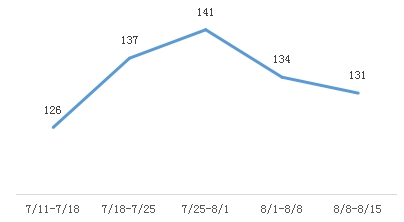
我们又往前抓取了四周的链上数据进行分析:从新增地址数(图6)来看,这几周新增地址数有所减少;
图6 2018年7月11日至8月15日新建地址数(万)
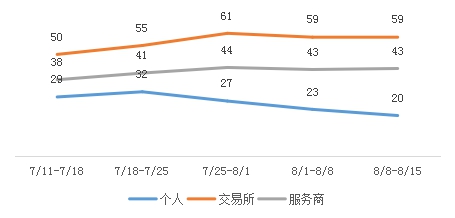
我们再将新增地址数用我们的算法进行分类(图7),可以发现:虽然交易所和服务商新增地址数在这几周内变化不大,但是新建个人钱包地址数却呈现明显下降趋势,直接导致了整体新建地址数下降。可以通过新建的个人钱包地址数减少判断,新进入市场的投资者人数有所减少。
图7 2018年7月11日至8月15日新建地址数按地址类型分解(万):
3. 交易量分析
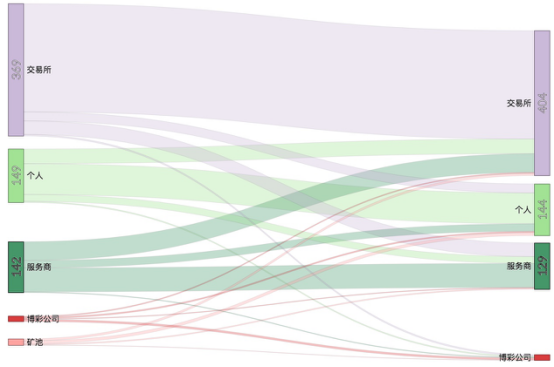
另外,除了对地址分析外,我们对该周的交易数据进行了分析。得到结果如图8所示。这周内一共有691万BTC的交易量,个人地址中的比特币转入交易所的量远远大于从交易所转入个人地址的量(相差14万BTC,约8.4亿美金),很大概率是有大量用户将个人钱包中的比特币转入交易所进行抛售,可能也是导致该周比特币价格下挫的原因之一。
图8: 2018年8月8日至8月15日所有比特币转账分布图(单位:万BTC)
4. 比特币价格下挫原因分析
2018年8月8日至8月15日数字货币整体低迷,比特币价格更是下挫15%。通过以上分析,该周比特币价格大幅下挫可能与两方面因素有关:
1)个人的新建地址数的减少,说明新入场的投资者人数的减少。
2)个人地址中的比特币转入交易所的量远远大于从交易所转入个人地址的量,很大概率是有大量用户将个人钱包中的比特币转入交易所进行抛售。
参考文献
[1]Fergal Reid and Martin Harrigan:An Analysis of Anonymity in the Bitcoin System
IEEE Third International Conference on Privacy,Security,Risk and Trust. Boston: IEEE,2011: 1318-1326.
[2]MAO Hong-liang,0 WU Zhen , HE Min , TANG Ji-qiang , SHEN Meng :Heuristic Approaches Based Clustering of Bitcoin Addresses
Journal of Beijing University of Posts and Telecommunications:TN911. 4 A
[3]Man H A,Liu J K,Fang J,et al. : A new payment system for enhancing location privacy of electric vehicles
IEEE Transactions on Vehicular Technology,2014,63 (1):3-18.
[4]Harry Kalodner, Steven Goldfeder, Alishah Chator, Malte Möser, Arvind Narayanan : BlockSci: Design and applications of a blockchain analysis platform
Cryptography and Security arXiv:1709.02489
[5]wikipedia:Random Forest
火币区块链应用研究院
关于我们:
火币区块链应用研究院(简称“火币研究院”)成立于2016年4月,于2018年3月起全面拓展区块链各领域的研究与探索,主要研究内容包括区块链领域的技术研究、行业分析、应用创新、模式探索等。我们希望搭建涵盖区块链完整产业链的研究平台,为区块链产业人士提供坚实的理论基础与趋势判断,推动整个区块链行业的发展。
“火币区块链大数据”是火币区块链研究院发布的数据产品,旨在打造最全的区块链数据库,为投资人、量化交易者、研究人员及区块链创业公司等区块链及加密资产市场参与者提供数据服务,以辅助各类参与者的决策判断流程。
免责声明:
1. 火币区块链研究院与本报告中所涉及的数字资产或其他第三方不存在任何影响报告客观性、独立性、公正性的关联关系。
2. 本报告所引用的资料及数据均来自合规渠道,资料及数据的出处皆被火币区块链研究院认为可靠,且已对其真实性、准确性及完整性进行了必要的核查,但火币区块链研究院不对其真实性、准确性或完整性做出任何保证。
3. 报告的内容仅供参考,报告中的事实和观点不构成相关数字资产的任何投资建议。火币区块链研究院不对因使用本报告内容而导致的损失承担任何责任,除非法律法规有明确规定。读者不应仅依据本报告作出投资决策,也不应依据本报告丧失独立判断的能力。
4. 本报告所载资料、意见及推测仅反映研究人员于定稿本报告当日的判断,未来基于行业变化和数据信息的更新,存在观点与判断更新的可能性。
5. 本报告版权仅为火币区块链研究院所有,如需引用本报告内容,请注明出处。如需大幅引用请事先告知,并在允许的范围内使用。在任何情况下不得对本报告进行任何有悖原意的引用、删节和修改。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号