本文共字,预计阅读时间。
曾经有个朋友满脸困惑地问起:“据说谷歌可以搜索到私人电子邮件,真的假的?”
回答前,需要解释一下网页爬虫的作用。今天,搜索引擎已经成为大家上网冲浪的标配,甚至有“内事不决问百度,外事不决问谷歌”的说法。搜索引擎可以根据用户的需要提供内容丰富的网上信息,相对于传统的纸质信息媒介,从根本上改变了人们获取及处理信息的习惯,极大提高了效率。而其基础就在于大量收集网页信息的网络爬虫。在搜索引擎发展的初期,程序猿小哥哥相互间炫耀的一个指标就是,自己的爬虫收集的网页数量。
网络爬虫
搜索引擎收集网上信息的主要手段就是网络爬虫(也叫网页蜘蛛、网络机器人)。它是一种“自动化浏览网络”的程序,按照一定的规则,自动抓取互联网信息,比如:网页、各类文档、图片、音频、视频等。搜索引擎通过索引技术组织这些信息,根据用户的查询快速地提供搜索结果。
具体来说,如果把互联网上的网页或网站理解为一个个节点,大量的网页或网站将通过超链接形成网状结构。人们浏览网页时,通过点击网页上的链接,从一个节点跳转到下一个节点,就像是在一张网上行走。网络爬虫模拟了该行为,但是速度更快,跳转的节点更全面,所以被形象地称为网络爬虫或网络蜘蛛。
随着网络的迅速发展,不断优化的网络爬虫技术正在有效地应对各种挑战,为高效搜索用户关注的特定领域与主题提供了有力支撑,也为中小站点的推广提供了有效的途径,为此,网站针对搜索引擎爬虫的优化(SEO)曾风靡一时。
爬取原理
需要说明的是,网络爬虫从一些初始网页URL(网页地址)开始抓取网页,在此过程中,不断从当前页面上抽取新的链接用于爬取,循环往复扩充到整个网络,为搜索引擎或大型网络服务商采集数据。
网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高。同时,由于待刷新的页面很多,所以通常采用并行的方式。
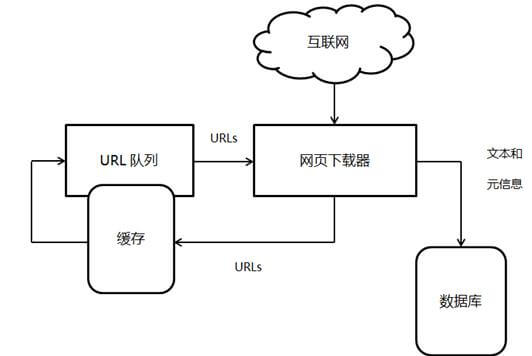
下图所示的是一个通用的爬虫框架流程。首先精心选择一部分网页,以这些网页的链接地址作为种子URL放入待抓取的URL队列中,爬虫从URL队列依次读取每个URL,通过DNS解析转换为对应的IP地址。然后将其和网页相对路径交给网页下载器,网页下载器负责网页内容的下载。一方面下载的内容存储到数据库中,等待后续处理;另一方面该网页的URL添加到已抓取队列(这个队列记载了已经下载过的网页URL,避免重复抓取)。此外,从刚下载的网页中抽取出新的URL,如果该链接没有被抓取过,则添加入待抓取URL队列,在之后的调度中下载对应的网页。这样循环往复,直到待抓取URL队列为空(实际上不会为空,会有其他的条件终止爬取),代表完成了一轮完整的抓取过程。
上述是一个通用爬虫的整体流程,由于互联网上网页数量太过巨大,在实践中通常会有不同的爬行策略,常用的有:深度优先策略、广度优先策略。网站典型的网页层次关系通常像一棵树,如果把主页看作树根,其他的网页则是枝杈上的树叶。具体来说:
(1)深度优先策略是在垂直方向上,逐个分支爬取,依次访问下一级网页,直到不能再深入为止。爬虫在完成一个爬行分支后,返回到上一链接节点搜索其它分支。当所有分支遍历完后,爬行任务结束。这种策略比较适合垂直搜索或站内搜索,但爬行页面内容层次较深的站点时会造成资源的巨大浪费。
(2)广度优先策略是在水平方向上,逐个层面爬取,优先爬行处于较浅层次的页面。当某一层次的全部页面抓取完后,再深入下一层爬行。这种策略能够有效控制页面的爬行深度,避免遇到一个无穷深层分支时无法结束爬行的问题,不足之处在于需较长时间才能爬行到目录层次较深的页面。
爬虫技术也面临着一系列的难题,比如:互联网上存在的大量重复网页、动态页面、动画特效页面等,增加了信息获取的困难。现有的搜索引擎能抓取的网页不超过互联网所有网页总数的一半,极端的估计是少于16%。
爬虫应用
坚持看到这里的宝宝要问了,枯燥的技术结束了吧?到底爬虫还有什么用呢?
众所周知,很多电商平台都有自动调价功能,它会依靠爬虫程序扫描同类网站商品的价格,针对性地展开相应的调整,从而取得价格优势,为销量提供保证。比如苏宁易购的“棱镜”系统就是一款实时比价工具。利用网络爬虫获取其他电商平台的同款商品的价格、促销、评论等商品信息,给业务人员的工作带来了极大便利。
其实,自从亚马逊十多年前推出该自动比价模式以来,机器人驱动的定价给整个零售行业带来了巨大的变革。以往,零售店最多每周调价一次,因为更换标签的成本和时间成本都很高。而在电子商务世界,零售商却可以随时调价,有时候甚至达到每天数次,这都得益于竞对定价数据等。
在电子商务行业,使用爬虫成为了一场“猫捉老鼠”的游戏。企业一方面希望阻止竞争对手爬取自己的网站,另一方面又想渗透对手的网站。尽管拥有各类技术防范,但爬取机器人数量还是令人震惊。除了竞争对手外,有的流量还来自科研院所,目的是研究竞争、搜索引擎、广告服务,甚至还有的是企图入侵网站帐号的不法分子。
爬虫安全性
到了这里,必须说下网络爬虫的安全性问题。由于网络爬虫的策略是尽可能多的“爬过”网站中的高价值信息,会根据特定策略尽可能多的访问页面,占用网络带宽并增加网络服务器的处理开销,不少小型站点的站长发现当网络爬虫光顾的时候,访问流量将会有明显的增长。
例如,某个网站上有一个10MB(如PDF格式)的文件,使用爬虫抓取该文件1000次,就会使网站产生大量出站流量(可在数分钟内达到GB级),引起的后果很可能是灾难性的。这种攻击达到的效果似曾相识,类似臭名昭著的DDoS攻击,使网页服务在大量的暴力访问下,资源耗尽而停止提供服务。
此外,恶意用户还可能通过网络爬虫抓取各种敏感资料用于不正当用途,主要表现在以下几个方面:
(1)网站入侵,大多数基于网页服务的系统都附带了测试页面及调试用后门程序等。通过这些页面或程序甚至可以绕过认证直接访问服务器敏感数据,成为恶意用户分析攻击的有效情报来源。而且这些文件的存在本身也暗示网站中存在潜在的安全漏洞。
(2)搜索管理员登录页面,许多在线系统提供了基于网页的管理接口,允许管理员对其进行远程管理与控制。如果管理员疏于防范,一旦其管理员登录页面被恶意用户搜索到,将面临极大的威胁
(3)搜索互联网用户的个人资料,互联网用户的个人资料包括姓名、身份证号、电话、邮箱地址、QQ号、通信地址等个人信息,恶意用户获取后有可能实施攻击或诈骗。
因此,采取适当的措施限制网络爬虫的访问权限,向网络爬虫开放网站希望推广的页面,屏蔽比较敏感的页面,对于保持网站的安全运行、保护用户的隐私是极其重要的。所以,谷歌正常情况下不应该抓取到私人邮件,但不排除特别情况下,由于服务器的管理漏洞而发生信息泄露的可能。
能坚持看到最后的童鞋必须有奖励,推荐一个搜索引擎shodan ,被称为“黑暗”谷歌,也被称为世界上最可怕的搜索引擎。它看上去跟普通搜索引擎一样,但是可以搜到网络上存在的摄像头、路由器、打印机等数据采集监控系统,并根据其所属国家、操作系统、品牌以及其它属性进行分类。如果说,谷歌和百度是网站内容搜索,那么,它则是网络设备搜索,在物联网应用中提供了探索的场景。
(微信公众号:苏宁财富资讯;作者:苏宁金融研究院高级研究员沈春泽)
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号