本文共字,预计阅读时间。
IP地址的所有研究,其实可以归到三个问题上:
1、这个IP在哪儿?(点击阅读:《互联网反欺诈:关于IP地址的方方面面(上篇)》)
2、这个IP是什么?(点击阅读:《互联网反欺诈:关于IP地址的方方面面(中篇)》)
3、这个IP干了什么?
本篇是关于IP地址研究的最后一篇文章,我们来聊一聊:如何分析一个IP地址做了什么?
上一篇中,我们提到了通过每个IP下的用户行为,判断用户群体的类型,进而给出IP地址的分类结果。那些,其实都只是最简单,最基础的一些分类方法。通过特定的指标计算、聚类算法,就可以得出结果。
然而,同盾的IP画像,是围绕反欺诈展开的,我们希望能够准确的评估一个IP地址的风险性,进而在风控策略中进行调控。
在IP画像设计初期,我们设计了一个风险评分,用于总体评价这个IP地址风险。风险分数中,IP是否有代理行为、是否命中已知的威胁情报、是否发生过风险行为,都作为评估的依据。但是这样的一个笼统的评分,在实际使用中却有诸多不便。
比如,我们曾经发现过一个IP地址,由于频繁的发生盗卡行为,最终我们给出的风险评分达到了94分(0~100,分数越高风险越高),然而这个IP下其他行为都是正常的,大量的正常用户通过这个IP进行登录、交易、支付等活动。
于是,我们萌生了一个想法,能否准确地定性一个IP到底做过什么样的坏事儿?
什么是坏事儿?
反欺诈中,涉及到的业务风险其实非常非常多。不同的行业、不同的平台都会有各自独有的一些风险。就拿“黄牛”来说,随着互联网的发展,黄牛也从最早的票贩子,演变出了很多很多的花样。
案例1:在各大航空公司的网上订票渠道中,存在很多“占座黄牛”,他们通过特定的渠道,订购了一定数量的廉价机票,然后加价转售,甚至会高出这张机票原有的价格。如果不能及时出手,黄牛就会选择退票,导致飞机上出现很多空座位,各大航空公司对此也很头疼。转手的过程很简单,只需要修改乘机人即可,这个行为可以通过线上的数据分析发现出来。
案例2:一些票务网站(专指演唱会、赛事门票),黄牛会注册大量账号,抢购演唱会门票,拿到门票后,加价出手。由于黄牛拿到了实体票,转手过程是在线下进行的,通过线上行为就无法进行监控。但是,在抢票过程中,黄牛为了增加自己抢到票的几率,会使用很多个账号重复下单,大量订单中的收获地址都是同一个或者具有极高的相似度。
案例3:美团、猫眼、格瓦拉等购买电影票的平台中,也存在很大数量的黄牛。尤其是一些热门大片儿的首映票,价格可以炒到很高。电影票的黄牛,往往以代购的形式操作,他们拥有很高折扣的会员卡,可以低价购买到电影票,然后适当加价转手。黄牛完成支付后,拿到取票二维码,然后把二维码发送给买家。这个过程,也是很难通过线上的行为来进行检测的。
如果我们需要分析一个IP到底做了什么坏事,就必须要先给出明确的定义,到底什么样的行为算是坏事。然后把这些行为分解为非常详细的特征指标,进行建模。
这个过程是漫长的,就像上面举的例子,同样是“黄牛”,由于不同的平台,不通过的行业类型,中间存在着非常巨大的差异。每一种行为都要做这样的深入分析和研究,其实我们一开始是拒绝的......
在后来的一段时间里,我们团队接到了越来越多的提问,客户希望知道,这个IP到底干了什么?到底有没有风险?我们只能硬着头皮,去提取这个IP在过去半年里的行为数据,然后逐一分析。说到底,单凭一个IP地址的类型和地理位置,远远无法满足风控的需求。最终,我们决定要做这么件事儿。于是好几个月就这么过去了。
首先,我们梳理了一份反欺诈的词表,用来给出各种欺诈行为的明确定义。
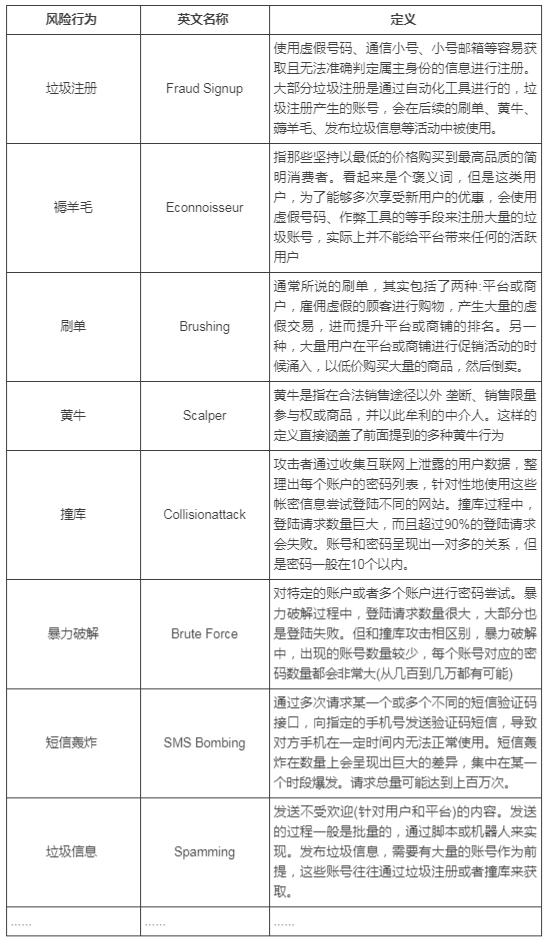
上面的列表中,是同盾反欺诈词典中一小部分,列举了一些对互联网公司来说最为常见的风险行为。
那么,接下来的问题就是要逐一对这些风险行为进行取样,分析其中的行为特征。
特征提取
篇幅有限,这里就简单介绍一下我们对黄牛(票务行业)做行为分析和建模的过程。
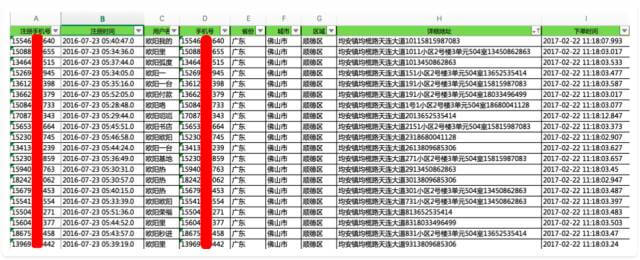
上图中,是我们抽取到的一份较为典型的黄牛抢票记录。
从这些记录里,能获取到怎样的信息呢?
1、这批账号都在同一天注册,并且注册时间较为集中,注册时间间隔大约为30秒;
2、每个账户只下一个订单,但是多个订单产生的时间非常接近,时间间隔仅为毫秒级;
3、多个订单中的收货人姓名很相似,直观判断,不太可能是真实的姓名;
4、多个订单中的收货地址有明显的异常,在末尾添加了无用的字符串;
5、收获地址末尾的字符串为11位的数字,比较像手机号,多个订单中的这个字符串相同;
6、账号注册和风险发生,中间存在较长的时间,可以定义为休眠账号或养号行为。
如果对这个地址做检查,我们会发现:广东省佛山市均安镇均榄路天连大道是真实存在的。
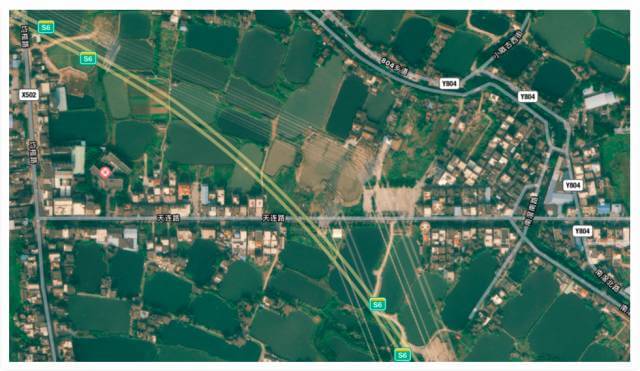
但是这附近并没有什么小区,反而更像是一个村子。也就是说,收货地址中,“天连大道”之后的部分都是随机添加的,可能并没有任何意义。
这样的做法,是为了避免平台对收获地址做校验,如果大量订单都寄送到同一个收获地址,那么这些订单都存在刷单的嫌疑。
上面的地图中,你可能也注意到了,其实并没有“天连大道”和“天连路”,其实是同一条街。但是由于名称不同,在地址核验过程中,就有可能被认为是两个不同的地址。类似的,比如“南京市白下区李府街”和“南京市秦淮区李府街”,也是同一条街道,2014年白下区被撤销,整体并入秦淮区。从行政区划上看,白下区已经不存在了,但是物流和快递大哥都知道,整个南京市就那么一条李府街,货物也可以成功地递交到收货人手中。
为此,我们也建立了一套用于对收货地址做真实性核验的系统,用于判断多个地址,是否指向了同一个地点。
除了前面列举的三个特征之外,还有一个比较隐蔽的特征,就是注册这些账号的手机号,其实都是”虚假号码“(参见:虚假号码【反欺诈专栏】互联网黑产剖析——虚假号码)。换句话说,提交这些订单的用户,其实都是通过垃圾注册产生的垃圾账户(虚假账户)。除此之外,通过设备指纹技术,我们也识别出,这些订单其实都来自于同一台PC。从IP维度上,虽然每个订单的来源IP都不相同,但是每个IP都最终被确认为代理或者机房。
以上种种,就成为我们判断黄牛行为的特征,归纳如下:
1、黄牛会事先通过垃圾注册准备一批可用的账号,注册过程中往往会使用虚假号码;
2、账号注册过程中会出时间、IP、设备上的集中性,即同一个设备,同一个IP上注册了大量账号;
3、多个订单中的收货人、收货地址不真实或相似度极高;
4、多个订单可能从同一个设备上产生;
5、提交订单的IP地址,大部分是机房IP或者代理IP;
6、垃圾账号注册完成之后可能不会立即进行抢票,而是经过了较长的沉睡期或进行特定的养号活动......
进一步细化之后,得到具体的指标参数,就可以进入训练模型的阶段了。
攻击链路
攻击链路(aka Kill-Chain),是安全领域中一个讨论比较多的话题。任何一次风险,都不会平白无故地发生,而是会有一个过程。对一次风险的定义,可以从最终的结果进行定义,但是更多的往往是对这个风险过程的定义。
以偷窃为例,一定会有这么几个步骤:
寻找目标 -- 蹲点 -- 标记 -- 作案准备 -- 撬门/扒窗 -- 进入房间 -- 寻找保险箱 -- 撬开保险箱 -- 拿走钱/珠宝 -- 清理现场 -- 离开现场 -- 销赃 -- 寻找下一个目标
上面的这些,就是Kill-Chain中的节点(Node),也可以叫做风险过程(Process)。在整个攻击链路中,只有起点和终点是确定的,剩下的部分,可能会没有,也可能因为各种突发情况而产生分支链路忽然中断,或者重复某些环节。多个攻击链路,会在特定的一个节点上汇聚,这个节点,就成为了风险防控的关键节点。在这个节点上进行防护,效果就会比较好。
欺诈风险,也是一样的。前面分析黄牛的特征中,我们提到了黄牛会使用一批垃圾账号进行下单。分析一个账号的欺诈行为,需要纵观这个账号的整个生命周期,或者在既定的时间片内,关联上下文,看用户的行为在每一个环节中是否符合特定风险的特征。
那么,针对黄牛风险,攻击链路就可以表示如下:
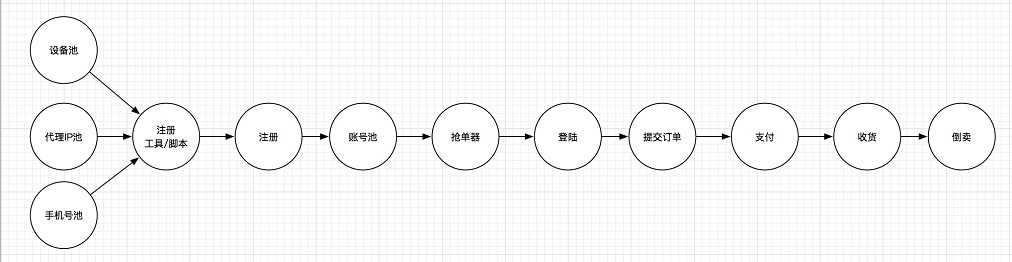
在攻击链路中,越是靠前的节点,发现和识别越为困难,因为各种特征其实并不明显,只能判断本次事件有嫌疑,而不能确定具体的风险。但是在这些环节上进行防护,起到的效果是最为显著的,成本也相对要低很多。
越是靠后的节点,发现和识别变得简单,很多特征都比较明显,但是防护就变得困难。并且,由于攻击链路本身会产生很多分支,可能在其他环节上已经产生了,即便是同一批次注册的垃圾账号,可能会在不同的场景中被使用。
此外,某些节点上会产生大量的分支链路,比如垃圾注册。通过注册工具/脚本,批量产生的垃圾账号,可能在后续的多种业务场景中出现,不同的业务场景中,又有着不同的风险。
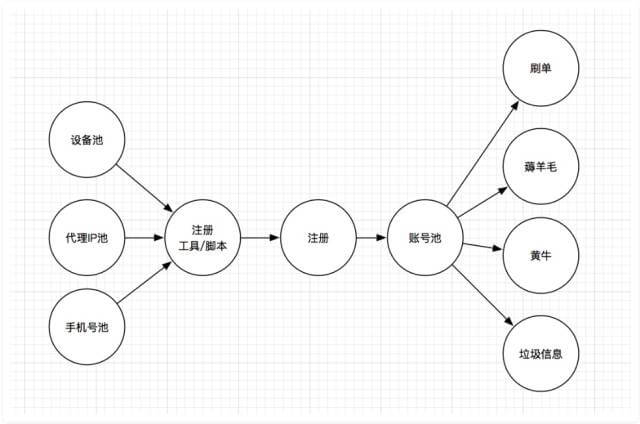
平台的业务越丰富,这个分支就会变得越发明显。如果一个平台同时提供了电商、电影票、团购、点评等多种线上业务,那么这个攻击链路就会变得非常复杂。
这也是为什么我们要建立IP地址画像、手机号画像和设备画像的原因。通过已知的各种风险行为,建立模型,通过跨平台、跨行业来进行联防联控,只要这个手机号、IP或者设备在历史上发生过一次风险行为,就会被识别出来,并且打上标记。
在整个攻击链路最开始的地方进行防护,并且在账号的整个生命周期中,进行持续监控,使得最终能够造成风险的账户数量降至最低。
在对抗中进步
这场欺诈和反欺诈的对抗,已经持续了多年,并且还将继续下去。
我们在不断提升检测能力、改进检测方式的同时,欺诈分子也在不断地产生新的作弊手段。并且,互联网在不断地寻求创新,同样是促销活动,在不同的平台上,会有截然不同的呈现方式,业务流程也不尽相同。这对我们分析风险行为,提取特征带来了极大的困难。
一旦新的业务模式产生,欺诈分子也会相应地寻找可供利用的业务逻辑缺陷,甚至产生一些新的风险类型。这需要我们不断地观察、学习和改进。为此,我们引入了无监督模型来辅助完成大量的指标提取工作。即使欺诈分子使用了新的技术、新的手段,特定风险的攻击链路是不会改变的,无监督模型可以从中提取出新的异常指标,再对模型进行优化和迭代。
结语
我们识别出的每一次风险行为,都会作为标签,标记在手机号、IP和设备上。即使欺诈分子不断地更换这些信息,也总会被发现出来。这些标签,目前在IP画像中已经可以使用,随着我们研究的进一步深入,越来越多的模型被开发出来,可以准确识别的风险行为也越来越多,力求让欺诈分子无所遁形。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号