本文共字,预计阅读时间。
如今,随着网上各类信息平台的发展丰富,很多用户在消费的时候已经习惯先看看网上的评论。比如,在网上购买一件衣服,除了会阅读商家的商品描述,还会浏览以往购买者留下的评论;再如,外出就餐或旅游,选择不熟悉的餐馆和酒店时,用户评论就是一个必不可少的参考项了。
从某种程度来说,口碑已经成了很多商家的产品与服务的质量记录。但是,对于网上看到的商户评价,你完全相信吗?
事实上,网上的很多好评,有不少都是“水军”刷出来的虚假点评。现如今,虚假的点评在全球都是一个让人头疼的问题,整个点评口碑界正面临潜在的严重冲击——因为人工智能也可以创造虚假点评,如泛滥后,将导致现有的点评信息的可信度急剧下降。
技术进步打开了一扇门
技术进步有时带来的不全是正面影响。芝加哥大学的研究人员开发了一个系统,可以在亚马逊、yelp 等网站自动生成假评论,而且跟用户的评论几乎没啥差别。其原理是:用网上已有的大量真实评论为训练素材,使用循环神经网络(RNN)进行学习,生成新的文本。因为生成的评论不是简单地从已有素材中复制,所以很难被识别出来。如下图中的几个例子:
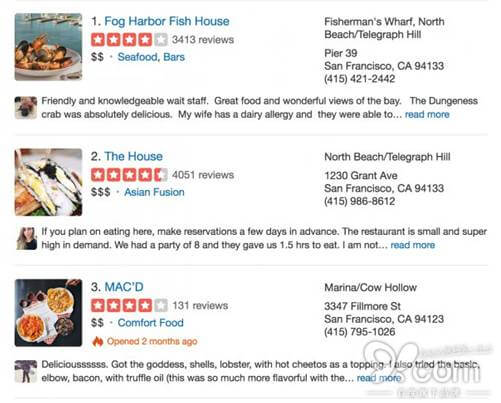
这些假评论不但骗过了系统的检测,甚至还被很多用户认可为“有用”。而在人工打分对比后发现,AI 生成的评论和真实评论的分值接近,也就是说,虚假评论可以影响用户的消费行为。
由此可以预见的一个结果是,人工水军的存在已经极大地影响了网络信息的真实性,而AI机器会将制造假信息的成本和难度大幅降低。
这里的假评论涉及的是文本自动生成技术,实现文本自动生成是人工智能走向成熟的一个重要标志,目标是能够像人类一样撰写出高质量的自然语言文本。这种技术有着广泛的应用前景,例如:智能问答、智能聊天、机器翻译等场景,实现更加智能和自然的人机交互。此外,它还能够替代人工编辑,实现新闻的自动撰写,这将可能颠覆新闻出版行业。对科研工作者而言,该项技术甚至可以用来帮助进行学术论文撰写,改变科研创作模式。
文本自动生成技术详解
下面,我们对文本自动生成技术做一个详细介绍。
根据输入的差异,文本自动生成技术分为:文本到文本的生成、意义到文本的生成、数据到文本的生成以及图像到文本的生成等几类。该技术极具挑战性,但是最近几年在业界已逐渐出现了一些具有国际影响力的成果与应用。
比如,美联社自2014年开始采用新闻写作软件自动撰写公司业绩的报道,大大减少了记者的工作量。美国已有多家公司能够提供新闻写作的软件与服务,文本自动生成不再是纸上谈兵的技术,已经在不知不觉中对我们的工作生活产生了影响。
在本文中,我们着重了解一下从文本生成文本、从数据生成文本这两个技术。
(1)文本到文本的生成
文本到文本的生成,主要是对给定的文本进行变换和处理,在此基础上得到新的文本,具体的技术包括:文本摘要、文本复述等。
文本摘要通过自动分析给定的文档,摘取其中的要点信息,最终输出一篇摘要,其中的句子可直接出自原文,也可重新撰写。目前主要是基于句子抽取,将原文中的句子进行评估与抽取。好处是易于实现,保证摘要出的句子具有良好的可读性。文本摘要主要包括两个步骤:一是对文档中的句子进行重要性计算或排序,二是选择重要的句子组合成最终摘要。
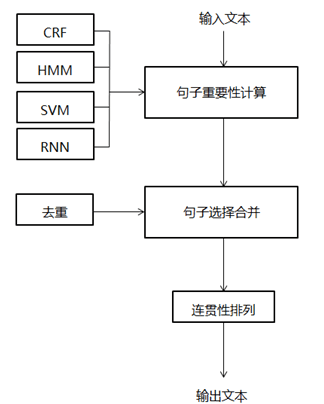
第一个步骤可采用基于规则的方法,利用句子在原文章中的位置或所包含的关键词来判定句子的重要性;也可采用各种机器学习方法(包括CRF、HMM、SVM、RNN等),综合考虑句子的多种特征进行重要性的分类、回归或排序。第二个步骤中,需要考虑句子间的相似性,去除重复的句子,并对所选择的句子进行连贯性排列,从而提高摘要的质量。
文本复述通过对输入的文本进行改写,生成全新的复述文本,一般要求输出文本与输入文本在表达形式上有差异,但表达的意思基本一样。比如:在机器翻译系统中可利用文本复述技术对复杂输入文本进行简化从而方便翻译,在信息检索系统中可利用文本复述技术对用户查询进行改写等。
简单的文本复述生成可以通过同义词替换来实现,也可以通过人工或自动构建的复述规则来实现,例如:他今天在网上买了一本书。 - 今天,他在网上买了一本书。当然,通过复杂的转换也可以使整段文本面目全非。
(2)数据到文本的生成
数据到文本,是指根据给定的数值数据生成相关文本,例如基于数值数据生成新闻、财经报道、医疗报告等。该技术具有极强的应用前景,已经取得了较大的研究进展,业界已经研制出多个面向不同领域和应用的系统。比如,英国阿伯丁大学提出了数据到文本的生成系统的一般框架,见下图:
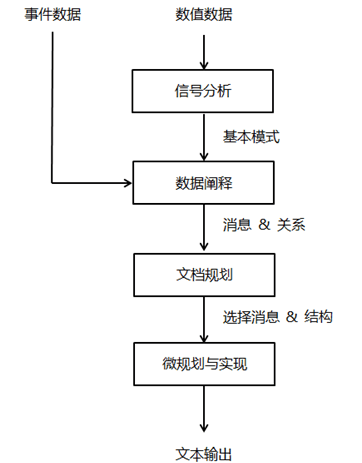
在图中,信号分析模块的输入为数值数据,通过利用各种数据分析方法检测数据中的基本模式,例如:股票数据中的峰值、长期的增长趋势等。
数据阐释模块的输入除了上阶段的基本模式外还有事件,通过对基本模式和事件进行分析,推理出更加复杂和抽象的消息,同时推断出它们之间的关系,最后输出消息以及消息之间的关系。例如:针对股票数据,如果跌幅超过阈值则创建一条相应的消息。消息之间的关系包括因果关系、时序关系等。
文档规划模块的输入为消息及关系,分析决定哪些消息和关系需要在文本中提及,同时要确定文本的结构,最后输出需要提及的消息以及文档结构。
微规划与实现模块的输入为选中的消息及结构,通过自然语言生成技术输出最终的文本。该模块主要涉及对句子进行规划以及句子实现,要求最终实现的句子具有正确的语法、形态和拼写,同时采用准确的指代表达。
由于数据到文本的生成技术的巨大应用价值,多家公司参与了相关研发,能够为多个行业基于行业数据生成行业报告或新闻报道,从而节省了大量的人力。比较知名的公司有 ARRIA、AI等。其中ARRIA是一家总部位于欧洲的公司,其核心技术是ARRIA NLG引擎。AI(AutomatedInsights)是由思科的前工程师创办的人工智能公司,最早提供基于体育数据生成的文本摘要,目前则服务于包括金融、个人健身、商业智能、网站分析等在内的多个领域。目前,AI公司已经为美联社等多家单位生成数亿篇新闻报道。
我国工业界也有部分单位研制了文本生成系统。例如:新华社开发了从财报数据生成企业财报年报的系统,该系统基于人工模板,将需要的数据填入写好的模板中,从而生成财报年报。
AI水军刷屏如何根治?
相对于大段自然语言文本的生成,AI对用户评论的模仿容易实现。因为每条评论内容都很短,主题统一而简单,对表达方式也不要求非常严格。这些虚假评论隐藏在众多真实评论中,人们不会抱着质疑的态度去看。对于数量繁多的信息大多数人会一扫而过,而这些假的评论被重复无数次之后,就会对人产生潜移默化的影响。
当然,面对AI水军,人们也不是束手无策。比如,社交平台上的机器人账号是虚假信息的一个重要来源,打击虚假信息也是每个社交平台都在做的事情。美国印第安纳大学和东北大学研究人员推出了Botometer系统,可以区分Twitter机器人和真实人类。该系统用超过 1000 项指标来监测用户行为,从推文发布的设备、时间、地点,到内容的原创比例,还有粉丝的构成等,这些数据最终会计算出一个分数,根据用户行为可判断账号有多大概率是机器人。
随着人工智能的发展,AI水军可能会给互联网带来冲击,进而降低网络的可信度,这时就需要有正确的措施来防范。具体怎么做呢?两点建议供参考:一方面,制定相应的政策法规和规范;另一方面,大力发展技术力量进行抵御。
(来源:苏宁财富资讯;作者:沈春泽 苏宁金融研究院高级研究员)
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号