本文共字,预计阅读时间。
本文的作者Ivy Nguyen是Zetta Venture Partners的投资者,曾为NewGen Capital的高级助理,并在ImageH2O管理创业加速器项目。本文中,作者基于当前数据爆炸时代的背景,探讨了数据对初创企业的重要性,并从数据收集、存储、管理、建模等各个过程中分析成本问题,同时提出了一些可能节约成本的方式。
目前,数据逐步成为AI创企的“金钟罩铁布衫”:初创企业收集的数据越多,就越能训练出更好的AI模型,使得新的市场竞争者难以与之匹敌。然而,这些数据并非免费获取,许多AI创企认为,这笔额外的费用大大侵蚀了他们的利润。随着时间的推移,这些公司可能希望降低在数据上的投入,但目前尚不清楚如何预测这种情况出现的时间,以及降低至何种程度,这就增加了公司对未来增长进行建模的难度。
在软件创企中,产品开发费用在损益表上归属于研发成本,而AI创企则将数据成本作为销售成本(cost of goods sold,COGS)的一部分,后者这种做法有助于企业发掘扩大规模同时降低成本的机遇,从而提高利润率。
下面的数据价值链流程图显示了大多数AI创企获取和使用数据的方式。首先,企业将基础事实的片段作为原始数据进行记录。企业可将原始数据存储在某处,然后建立流程或途径进行维护和访问。在运用于AI模型之前,企业需要对数据进行标注,以便AI模型实施处理每个数据点的行为。随后,训练有素的模型接收数据并产生反馈,企业便可以使用这种反馈来执行驱动终端用户某种行为的操作。该过程可以分为三个不同的步骤:获取数据、存储数据和为了训练模型而标注数据。每一步都会产生相应的成本。
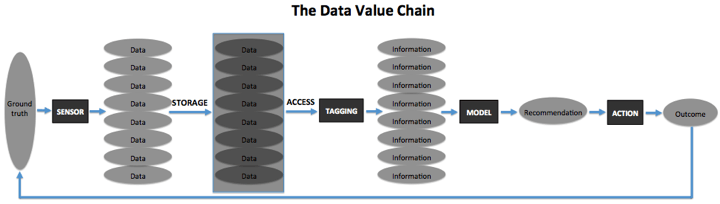
数据采集成本
在所有的数据价值链中,任何传感器(无论是物理设备还是人类)在收集原始数据时,首先需要捕捉对现实的观测。在这种情况下,数据采集的成本将来自于传感器的创建、分配和操作。如果该传感器是一种硬件,企业必须考虑材料和制造的成本;如果传感器是人,则成本来自于人员的招募以及提供他们制作和记录观察结果所需的工具。根据覆盖范围的不同,企业可能需要支付大量的费用来分布传感器。不仅如此,在某些用例中还可能需要进行高频率的数据收集,这也可能会增加人工和维护成本。例如,受众测量公司尼尔森(Nielsen)就需要承担上述所有成本,因为它既提供收视率收集盒,也需承担获取参与者电视节目观看情况的许可费。这样一来,随着覆盖范围越来越广泛,尼尔森的数据就越有价值,规模经济也就自然而然降低了单位数据采集成本。

在某些用例中,企业向终端用户提供管理工作流程的工具(例如,自动电子邮件响应生成器),将他们捕获的数据存储在他们的工作流程中,或者观察他们与工具的交互并将其记录为数据,从而将数据采集的工作和成本转移给终端用户。如果企业选择免费分布这些工具,那么数据采集的成本就将是获取用户的成本。或者企业可以选择对工作流工具进行收费,这种方式可能会减慢和限制客户采用率,从而在抵消数据采集成本的同时减少数据采集,具体的降低和限制程度将取决于企业对该工具的定价。
例如,我们公司的投资组合之一,大数据公司InsideSales为销售代表提供了一个可直接与销售线索建立联系的平台。在销售代表使用的过程中,平台会自动记录互动的相关数据,例如时间、模式、其他元数据,以及该销售渠道中的销售线索是否有进展。这些数据将被运用于AI模型的训练,从而计算出联系潜在客户最佳的通信时间和通信方式。在这种情况下,随着越来越多用户入驻该平台,网络效应就有可能会提高工具的实用性,从而降低获取用户的成本。
另外一种方式是,在另一个实体已经建立了数据收集渠道的情况下,确保建立战略伙伴关系可以进一步降低成本。例如,我们的另一家公司Tractable采用计算机视觉来实现汽车保险调节器的自动化。该公司目前正与几家业内出色的汽车保险公司合作,致力于研发获取受损汽车图像的技术。除此之外,我们无需使车主下载应用程序,从而节约了应用程序推广所需的成本。
存储和管理成本
在数据存储和访问方面,初创企业也面临着一个成本问题。除了数据收集之外,企业可能还需要客户提供其他相关数据来丰富模型。由于许多行业近期才逐步实现数字化,因此任何拥有企业所需数据的潜在客户都不容小觑。为了获取这些数据,企业可能会在低利润率的数据准备工作中花费大量的人力。

此外,如果数据分布在不同的系统和孤岛中,那么企业可能需要花费大量的时间来构建各个集成,从而使模型完全正常运行。有些行业围绕整体式和异质性技术堆栈建立,使集成很难在客户之间重复使用。如果无法获取集成服务提供商,那么这家AI创企很快就可能发现自己陷入了这样的泥潭:只有为每个新客户构建定制集成,才能部署其AI系统。数据的结构方式也可能因客户而异,这就要求AI工程师花费额外时间对数据进行规范化或将其转换为标准化模式,从而应用AI模型。企业可以采用建立公共集成库的方法降低成本,因为它可以在新客户中被重复使用。
训练成本
大多数建立AI模型的方法都需要对数据进行标注,这对AI创企来说是最大的和最可变的成本之一。如果这些示例简单明了或是通俗易懂,外行人就可以进行标注。例如,在图片中画一些苹果,然后在所有苹果周围画一个框,即可标注为外包劳务服务。
但有时,注释需要更多的专业知识和经验,例如根据视觉线索来确定苹果的质量和成熟度,或者判断石油钻机上的一小块锈斑是否具有风险。对于这种更专业的劳动力,企业可能需要建立一个高薪的内部专家标注团队。根据企业的标注方式,可能还必须构建自己的标注工作流工具,尽管Labelbox等公司目前已经开始提供此类工具。
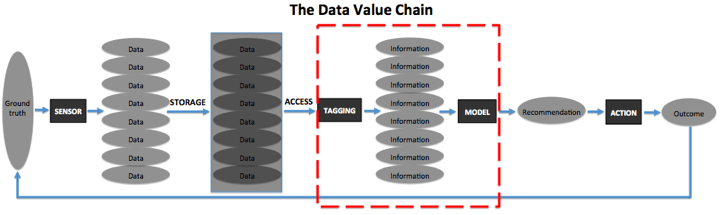
在某些AI应用程序中,终端用户会是最有效的标注器,企业可以通过设计产品来减轻标注成本,这样用户就可以在与产品交互时进行数据标记。例如,Constructor提供针对电子商务的人工智能网站搜索,观察用户实际点击和购买每个产品的搜索词,使这些网站能够优化搜索结果从而获得更高的销售额。这种标注不可能通过外包或专家搜索服务进行人工操作,而且这种方式大大节约了Constructor潜在的巨额标注成本。
即使受到了高精度的训练,但当模型无法确切地解释一项新输入的内容时,仍然需要进行偶尔的人工干预。根据模型向终端用户传递价值的方式,该用户自己可以对模型进行更正或标注,企业也可以通过使用质量控制的“AI保姆”来处理异常。如果企业正在建模的环境不稳定且变化速率很高,那么企业可能需要在稳定状态下保留一组标注器,以便根据需要使用新的数据更新模型。
扩展AI业务
第一批成功的AI企业进入市场时,通过提供无AI的工作流工具来捕获训练AI模型的数据,并且该数据最终提高了工具的价值。这些初创企业在早期就能够实现软件利润,因为数据和人工智能在其价值主张中居于次要地位。然而,随着市场转向更专业的AI应用,下一波AI创企将面临更高的启动成本,并将耗费更多的人力来为客户提供初始价值,导致其成为低利润率的服务企业。
获得大量客户和数据最终将降低单位经济效益和构建至关重要的复合防御能力,但许多初创企业并不确切地了解这一点,也不明白他们需要采取哪些行动才能更快地实现目标。而出色的AI创企则会通过这种方式进行优化权衡,有计划地进行投资并迅速扩张。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号