本文共字,预计阅读时间。
2019年4月13日的下午,在上海普华永道创新中心开启了一场金融知识图谱的产业化落地会议,邀请了多位行业专家,有来自东南大学、上海财经大学、复旦大学的专家,以及文因互联等智能金融技术与服务的业内专家。
从知识图谱理论、场景实现、发展路线的探讨、挑战与机遇、困境与破局等不同的角度对金融知识图谱的产业化落地之路进行分享与交流。
所涉及的演讲主题有智能金融的破局与金融知识图谱、探讨知识图谱的成功之路、寻找缺失的因果链——浅谈当前各行业知识图谱落地中的挑战与机遇、金融智能问答系统落地浅析。
关键主题是智能金融、知识图谱、落地,他们虽然从不同的维度去分析,但在某些观点上能够起到相互补充和印证。听完之后,启发良多,因此结合我当时做的一些笔记,试图把他们所讲整合成一个较为清晰的脉络。
一、人工智能+金融的应用
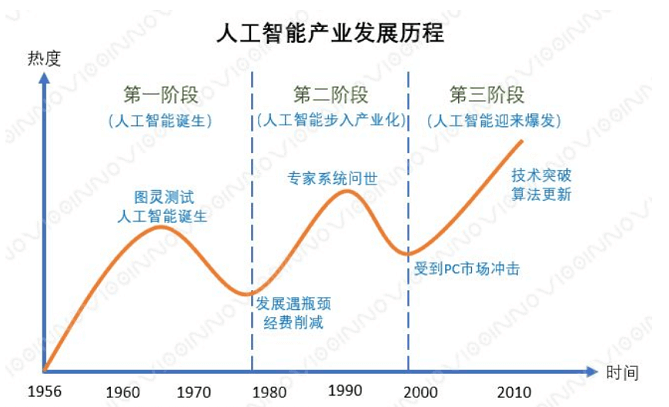
人工智能的发展经历了几次高潮和低估,当一项技术没有办法得到很好的应用时,会受到市场的质疑,进而资本退去。AI能够在多个方面助力金融的发展,从效率上可提高金融机构工作效率,价值上辅助投资决策,提高合规监管的质量与效率,以及有效预防规避金融风险。
前几年,金融领域的智能投研、智能投顾得到市场的很多关注,智能投研通过深度学习、自然语言处理、知识图谱等方法,对数据、事件、结论等信息进行自动化处理和分析,为金融机构的专业从业人员(如分析师、基金经理、投资人等)提供投研帮助。但国内智能投研领域的发展与应用远不如预期,大规模场景化的服务仍在推进过程中。
智能投顾又称机器人理财,是虚拟机器人基于客户自身理财需求,通过算法和产品来完成以往人工提供的理财顾问服务,而目前也是概念重于形式,有关这些高大上的AI金融应用的报道当时在互联网上满天飞,但如果不了解行业的实际应用情况,渐渐就会模糊AI+金融的意义在哪里?会议上,专家提出了如下几个核心观点:
1. 智能金融的本质:其本质是金融信息处理的部分环节中间件化,金融大工业不是超出市场收益率的投资决策,而是建立金融信息处理的协作系统,直奔主题的金融智能系统并不行得通。
的确,在蚂蚁金服,他们就有专门的中间件团队,打造了大量的金融中间件,如果金融大工业是为了找出超出市场收益率的投资决策,那想必这些公司在下一刻就不会存在了,因为大家都忙着躺赚了。
AI正尝试和金融结合,但技术的落地需要过程和尝试,如果试图从一开始就设计一个完备的系统,可能不太现实,给市场带来过高的期望,反而会跌的更重。AI技术的发展也经历好几个阶段,这种演进性也从某种程度上决定AI与行业的结合是有其所处阶段的局限性的,不妨先从简单环节下手,一个切实可行的复杂系统势必是从一个切实可行的简单系统发展而来。
2. 金融IT发展的四阶段:信息化(从线下到线上)、大数据化(从割裂到融合)、自动化(从繁琐到简单)、智能化(从画龙到点睛)。
目前,我们正处于自动化阶段,尤其是现在面临着数据量增加和非结构化信息的增加,如何能够自动化地处理复杂数据成为一个较大的问题,在数据分析中有过半的精力都是花费在清洗脏数据上,提升了人力成本,也影响后面环节的应用。
二、知识图谱在人工智能中处于什么样的角色
经过上面的分析,我们知道技术对金融行业的升级一定离不开技术本身,如何缩小技术和应用落地之间的差距是一个亟需关注的问题。
之前,我们听到更多的是大数据的应用,如何利用大数据价值进行变现,这些数据很多都是结构化的数据,而实现人工智能,存在两种基本范式:
1. 在数据驱动下的统计学习,深度学习。
2. 符号化,才有理解、解释和推理。
所谓的“符号”我们可以理解为我们人类所积累的经验、知识、文字等内容。大家都使用过百度的搜索引擎,根据用户输入的关键字提示完整的问题,其中的原理会使用到统计的知识。比如,我根据大量的中文语料来统计出,哪一句话最像人说的话。
但这种基于统计得出的结果并没有真正理解数据、文字的意思,就像我们和智能机器人说话一样,总觉得他们傻傻的,因为他们没有人的背景知识、所处的环境信息,就无法对人的信息像人类一样进行解码解读。
那我们一定要处理那些复杂的自然语言等符号化信息吗?人工智能就不能只处理简单的数据吗?
引用当时一位专家的话来回答:
“符号知识是人类智慧的最大载体,因此符号知识用于实现机器智能是对人类智慧最重要的继承方式之一。”
大数据智能的重要使命是从统计关联挖掘因果关联,相信大家听过一个经典的数据分析案例:啤酒和尿布,我们可以根据数据分析出事物之间的关联性,但是我们却不知道原因,这种不具有解释性的结果使得我们很难相信数据分析到底能给我们带来多少实在的价值。
如果让机器人能够真正理解这些数据,那么就能给我们提供可解释性的结果,而知识图谱使得机器具备“理解”能力成为可能。
知识图谱,简单来说,就是构建一张知识网络,类似于人脑中的背景知识,它试图构建出事物(圆形的节点表示)之间的关联(节点之间的连接线),有了这张网络,计算机能够进行推理,从而找出事物之间的关联路径,现在垂直领域的知识图谱往往来自某公司的业务型数据库。

三、知识图谱落地挑战巨大
现在我们知道了,人工智能要想再往前走,离不开对数据的“理解”,而这种理解可以依靠知识图谱来实现。但知识图谱的构建困难重重,具体体现在:
• 构建知识图谱涉及较多环节,技术栈比较长,每个技术都有很多参考文献,实现周期较长。
• 构建知识图谱的过程会应用到自然语言处理、机器学习等内容,离不开大量标注数据的训练,而标注数据需要耗费巨大的人力成本,如果构建知识图谱的成本非常大,那么就离应用又远了一步。
• 知识图谱的人才缺乏。
因此,会议中的专家提议,建立知识图谱平台,它能够:
• 有机集成各种知识图谱的技术
• 汇集各种知识,包括通用知识和行业知识(不同的行业建立的知识图谱是不一样的)
• 应具备知识服务能力
• 具备多行业应用能力
• 降低知识图谱构建门槛
• 降低知识图谱专业人才离职的风险
这样才能更加有效地把知识图谱推向行业落地,而行业落地会产生更多的数据及应用需求,才能够反哺知识图谱的发展,否则,知识图谱的研究容易与实际需求产生脱节。
四、知识图谱应用在金融行业中的必要性和可行性
1. 必要性
要推动人工智能和金融的深度结合,知识图谱在其中的作用不容小觑,但现在很多传统类金融企业对知识图谱还不甚了解,同时,目前的知识图谱应用还未体现出较大的商业价值,因此很多金融智能服务企业在服务于B端金融企业时,还要竭力科普一番。
我们会发现很多服务平台都推出了智能客服,工商银行的叫工小智,京东智能客服叫JIMI,虽然这些客服都傻傻的,远没有达到用户的使用预期,那为什么各家企业还要争相开发呢?
这源于微软提出的 “对话即平台”的理论。
在过去的PC端时代,浏览器即入口,到了移动互联网时代,触屏手机即入口,那么在未来的人工智能时代,入口是什么,也许就源于用户与平台之间的对话,这种对话拉近了用户与计算机之间的关系,谁更智能,谁能更好地理解用户的需求,就能更好地抓住用户。
而这些智能客服都离不开知识图谱的应用。
在金融的反欺诈领域,传统反欺诈主要依赖信息的人工审核,但身份证、手机号码、银行流水等材料的伪造成本低,金融机构需投入大量人力审核信息主体的身份及材料的真实性;
大数据反欺诈是通过收集大量异构、多样化的信息交叉验证信息主体提供的信息及第三方信息来源的真实性,比传统反欺诈更具有较强的反欺诈能力。但由于数据来源多、数据异构碎片化,结构、半结构、无结构的数据共存,且规模日益庞大,如何整合多元异构数据源,利用已有数据交叉验证成为新挑战。
而知识图谱反欺诈,能够将多源异构的大数据整合成机器可以理解的知识,将“单点”的身份、资料等的核查转换成从“面”的形式(网状)进行欺诈风险检测,从而实现欺诈的识别与防御。就好像事先编制了一张相互关联的网,而欺诈的行为能够通过交叉验证得到发现。
2. 可行性
对于中小型金融企业来说,他们更加关注知识图谱在金融领域的落地是否具有可行性,在会议上专家给出了几点工程实践上的建议:
• 循序渐进:错误想法是想要速战速决,毕其功于一役,应该做好打持久战的准备
• 先简后难:从一些词汇、简单关联、结构化程度高的反推做起,不要依赖不成熟的文本抽取
• 应用引领:从应用反推知识的种类与边界,从应用中获得反馈,不要为了建图谱而建图谱
• 由粗到细:从粗粒度知识表示做起,避免过早陷入细粒度知识表示的泥潭
这些建议对很多行业应用知识图谱都有借鉴意义,金融的核心在于风险控制,而各行业的知识图谱的发展能够给金融行业带来更多可用的数据,比如现在的用户资质审核会使用到更加丰富的数据,包括行为数据、社交数据等,而在过去,这部分数据是很难获得的。
再例如我最近在做一个关于简历和职位的匹配项目,我们是不是可以建立一个员工和跳槽前后公司的关系,根据图谱,我们发现最近有大量的人才从制造业往互联网业跳槽,这是不是意味着接下来一段时间互联网行业的股票会上涨,因为人才的流动可能关系着行业的兴衰。
总结来说,知识图谱的发展能够促进人工智能的发展,更进一步推动人工智能与行业的结合,但由于目前技术上的问题,中小企业在资金资源、人才资源缺乏的情况下,可以先从简单的系统做起,逐步演进。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号