本文共字,预计阅读时间。
一、词的表示方式
数据的表示是机器学习的核心问题。在语音识别中,可以把音频的频谱序列向量所构成的matrix矩阵作为输入,在图像识别中,可以把图片像素构成的矩阵作为输入。而在自然语言处理中,我们也希望可以将每一个词用一个向量表示出来。文字和图像、语音的区别在于,图像、语音属于比较自然的低级数据表示形式,我们想判断两个信号是否相似,可以通过一些距离度量来进行判断。但是语言作为一种高层的抽象工具,只要两个词的字面不同,就难以刻画它们之间的联系。

最经典的词的表示方法就是,将每个词表示为一个很长的向量。这个向量的维度是词表的大小,其中绝大多数元素为0,只有一个维度为1的值,这个维度就代表了当前的词。这种简洁的表示方法配合上最大熵、SVM、CRF等算法已经很好地完成了NLP领域的各种主流任务。

二、PLSA主题模型
主题模型可以将每篇文档的主题以概率分布的形式给出,通过分析一些文档抽取出他们的主题后,便可以根据主题进行主题聚类或文本分类。
主题模型是一种典型的词袋模型,就是我们有一个前提的假设是一篇文章是由一组词构成的,词和词之间没有先后的顺序关系。也就是说一篇文章如果将所有词打乱顺序再重组,和原来的文章可以认为是等价的。并且,一篇文章可以包含多个主题,文档中每一个词都是由其中的一个主题生成的。
频率学派认为一篇文章是这样生成的,我们有两种骰子,一类是由文档生成主题的色子,每个色子有K个面,每个面代表了一个主题。还有一类是由主题生成单词的色子,每个色子有V个面,每个面代表了一个词。由主题生成单词的色子有K个,编号从1-K。在生成一个文档之前,我们先制造了一个特定由文档生成主题的色子。在重复如下步骤:投掷文档生成主题的色子,得到编号Z,选择K个主题生成单词的色子中编号为z的那个,投掷后,得
到一个单词。
那么一篇文章中出现某个单词的概率就可以求得:
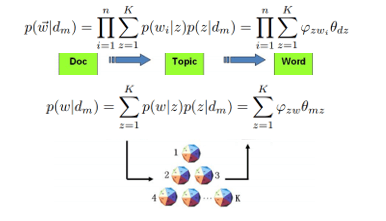
一篇文章中出现这种给定的单词组合的概率就是:
这是频率学派的PLSA模型,这个模型的参数可以通过EM算法进行估计。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号