本文共字,预计阅读时间。
短文本相似度,顾名思义是指长度较短文本(在中文中一般小于50个字符)的相似度计算,一般用于搜索引擎、智能问答、知识检索、信息流推荐等系统中的召回、排序等阶段。
1. 短文本相似度基本介绍
短文本相似度的计算方式,最基本的分为无监督和有监督两种方式。无监督方法的好处是不需要训练数据,方法可以直接通用于任何场景,缺点是准确度一般,常用于冷启动的场景。有监督的方法,可以在特定的场景下通过有标数据来定制化相似度模型,从而提高准确率。
无监督方法介绍:无监督方法有基于词汇重合度的TFIDF、BM25、Jaccard、cos等,基于浅层的语义主题模型LDA、PLSA等,基于语义encoding的word to vector、pretrained encoder(例如XLNet[1]、BERT[2]、ELMo[3])等,以及基于以上各种方法的相似度分数的经验加权叠加。
有监督方法介绍:有监督的方法可以为基于传统的分类模型,如LR、SVM、GBDT等,以及基于深度神经网络的模型。基于深度神经网络的模型普遍分为两种思路: representation-based 模型(SE)与interaction-based 模型(SI)。representation-based 模型主要基于 Siamese[4] 网络结构,双塔共享参数,将两个文本映射到同一空间,再计算相似度,例如DSSM[5]、CDSSSM[6]、ARC-I[7]等等。优点是结构简单,可以用于构建索引等场景,缺点是两个短文本的编码完全独立进行,无法考虑任何短文本内部之间的关联。interaction-based模型为了解决上述问题,提前将编码的过程加入了短文本内部之间的关联参数矩阵,更好地把握了语义焦点,能对上下文重要性进行更好的建模,例如:ARC-II[7]、MatchPyramid[8]、MVLSTM [9]等。
随着近年来NLP的发展,研究发现,有监督的方法虽然准确率高,但是有标数据的获取成本太高,因此迁移学习(迁移学习是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中,一般两种任务之间需要有一定的相似性和关联性)的效果越来越凸显出来,并在各种NLP(包括短文本相似度)场景出现了革命性进展,例如2018年google提出来的Bert模型以及2019年google再次提出来的XLNet模型,都在各项NLP任务上取得了颠覆性的突破。其中,google 2008官方发布了pre-train的BERT中文预训练模型,给BERT在中文市场工业界的应用做了良好的铺垫,而哈工大最近也发布了基于XLNet的中文版预训练模型,地址为:https://github.com/ymcui/Chinese-PreTrained-XLNet。基于这些预训练模型,我们可以很方便地快速进行中文NLP任务的迁移学习,以及进行落地应用。其中,Bert借用了Transformer结构中的encoding部分,如下图的左边部分来对文本进行编码:
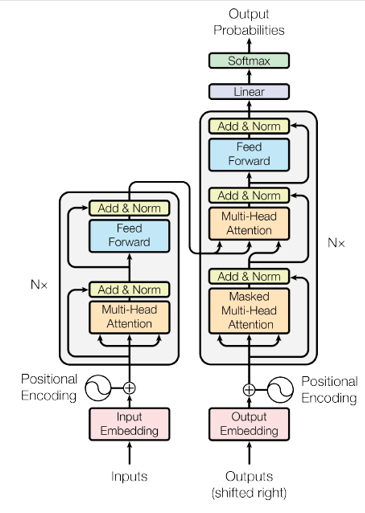
类RNN结构由于能够比较有效地捕捉句子的语义序列信息,常被用于文本序列的编码和解码,但其计算有前后状态信息依赖,因此性能瓶颈比较突出[10],而transformer结构抛弃了RNN,基于Self-Attention,并引入了Positional Encoding,既能够有效地捕捉文本字符间的位置关系,又能并行计算以提高计算效率,只需要在大量的无监督数据集上进行模型的预训练(例如语言模型的预训练和句子上下句关系预测的预训练),并在特定任务集合上做少量的fine-tune,便可以达到一个很不错的效果。当然,Bert的预训练过程也并不是完美无缺的,Bert的预训练语言模型目标函数的计算过程强行做了独立性假设,并且,基于随机概率MASK的预训练文本和基于具体任务的整句文本fine-tune的过程,具有明显的不一致性,综上考虑,XLNet被提出,为了解决双向上下文的问题,XLNet引入了排列(permutation)语言模型。排列语言模型在预测时,需要预测目标的位置信息,因此将传统的Self-Attention修改为Two-Stream Self-Attention来捕捉位置信息,计算过程如下:
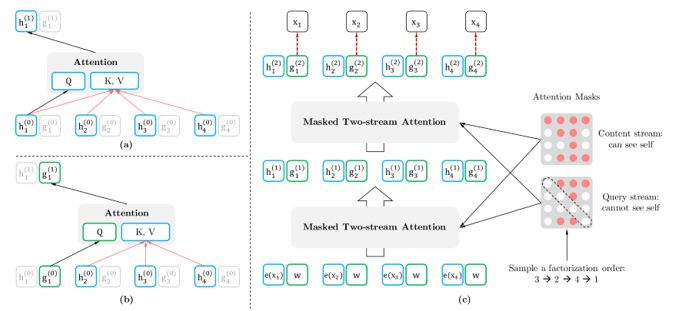
XLNet还借鉴了Transformer-XL的优点,它对于很长的上下文的处理是要优于传统的Transformer的。
2. 金融智能客服系统中的实践方案
基于以上的背景,在自研的金融智能客服系统中,我们定制化开发了一套基于知识库的FAQ单轮智能问答回复系统。由于知识库的变更较快,知识库的维护人员往往专业性较差,因此业务系统在实现知识库问题的相似度匹配时,往往需要更考虑通用性。我们提供了两种不同模型选择,一种为通用相似度匹配模型,另一种为自定义相似度匹配模型。
通用相似度模型的相似度计算方式为: score = ,其中,N=6,分别为:字符维度cos相似度、term维度cos相似度、词性维度cos相似度、命名实体识别维度cos相似度、word2vec sentence编码维度cos相似度,BERT transformer第一层sentence编码cos相似度。其中在训练word2vec的term编码时,我们整理了公司内部金融领域已有的一些客服历史对话,以及金融领域的相关语料,再结合百度百科、维基百科、人民日报、知乎、微博等相关通用语料进行重训练,最终用average pooling的方式表征sentence维度编码。而BERT依然选用average pooling的方式,并直接选用官方开放的预训练模型,进行layer选参的实验,在融360APP的贷款客服数据以及阿里金融通用数据中,对BERT不同layer进行单维度分数测评实验表明:layer=1并且序列长度=25时,效果最佳。除此之外, 为超参,可进行手调,也可以在较少数据集上进行简单的线性回归学习,来决定每一个维度分数的权重。
在通用模型之外,我们也提供了几种常用的自定义相似度模型,例如MV-LSTM、BERT、XLNet等可进行业务定制化训练,这些模型都已经准备了预训练版本,可在相对较少的数据上直接进行fine-tune,以免发生明显的过拟合。
3. 总结与展望
目前,无论是金融领域客服还是通用领域客服,单轮的智能回复一般能拦截超过50%的问题,剩下的问题,往往是通过多轮多次的对话逐渐表述清楚。因此,基于多轮会话的智能客服,将是下一步的重点。我们也开发了一套基于flow-chat、intent-slot识别的多轮对话系统引擎,准备逐步迁移自适应智能客服系统。另外,基于知识库的FAQ问题,效果很大程度取决于知识库的数量以及质量,这给系统的使用人员造成了很大的负担,系统将通过数据挖掘的方式,逐步用自动化的方式从用户与客服历史的对话中,挖掘出新的问题或问题-答案对,以进一步提升使用管理员的工作效率。
引文
[1] XLNet: Generalized Autoregressive Pretraining for Language Understanding. Z Yang, Z Dai, Y Yang, J Carbonell . arXiv preprint, 2019
[2] Bert: Pre-training of deep bidirectional transformers for language understanding. J Devlin, MW Chang, K Lee, K Toutanova. arXiv preprint, 2018
[3] Deep contextualized word representations. Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. arXiv preprint, 2018
[4] Learning a similarity metric discriminatively with application to face verification. S Chopra, R Hadsell, Y LeCun. CVPR (1), 2005
[5] Building Deep Structured Semantic Similarity Features to Improve the Media Search. 2013
[6] A latent semantic model with convolutional-pooling structure for information retrieval. Y Shen, X He, J Gao, L Deng, G Mesnil. Proceedings of the 23rd ACM, 2014
[7] Convolutional neural network architectures for matching natural language sentences. B Hu, Z Lu, H Li, Q Chen. Advances in neural information…, 2014
[8] Text matching as image recognition. L Pang, Y Lan, J Guo, J Xu, S Wan, X Cheng. Thirtieth AAAI Conference on …, 2016
[9] A deep architecture for semantic matching with multiple positional sentence representations. S Wan, Y Lan, J Guo, J Xu, L Pang, X Cheng. Thirtieth AAAI Conference on …, 2016
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号