本文共字,预计阅读时间。
“放下你手里的代码,小心被抓。”
最近程序员圈子不乏这样的戏谑调侃。
原因是最近发生的多起涉及爬虫技术的公司被司法部门调查。近日,51信用卡被查,更是将暴力催收背后非法使用爬虫技术爬取个人隐私数据的丑行,暴露在阳光之下。
一时间,“爬虫”成为众矢之的,一些公司紧急下架了爬虫相关的招聘信息,给大数据风控、人工智能从业者带来些许恐慌,头发又多落了几根。
实际上,大部分人都听说过爬虫,认为爬虫就是到人家网站上去爬东西、偷数据,有些人甚至认为只要有爬虫,什么数据都可以搞到。
今天,我们就打开爬虫这个“工具箱”,把涉及到的技术盲区放到灯光下,让大家可以清楚地看下。下面,本文就从这个角度来聊聊爬虫这个熟悉而又陌生的技术。
一、爬虫的技术原理
搜索引擎收集网上信息的主要手段就是网络爬虫(也叫网页蜘蛛、网络机器人)。它是一种“自动化浏览网络”的程序,按照一定的规则,自动抓取互联网信息,比如:网页、各类文档、图片、音频、视频等。搜索引擎通过索引技术组织这些信息,根据用户的查询,快速地提供搜索结果。
设想一下,我们平时浏览网页的时候会怎么做?
一般情况下,首先,会用浏览器打开一个网站的主页,在页面上寻找感兴趣的内容,然后点击本站或其它网站在该网页上的链接,跳转到新的网页,阅读内容,如此循环往复。如下图所示:
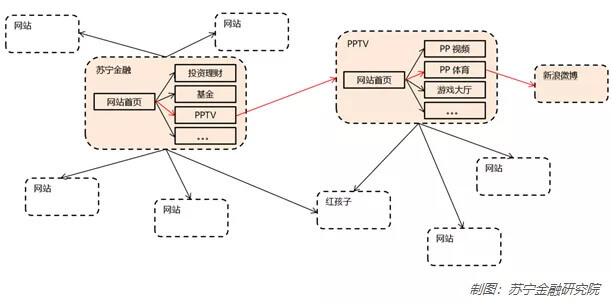
图中的虚线圆角矩形代表一个网站,每个实线矩形表示一个网页。可以看到,每个网站一般以首页为入口,该首页链接到几个、几万个、甚至上千万个的内部网页。同时,这些网页往往又链接了很多外部网站。例如,用户从苏宁金融的网页为起点,浏览发现了PP视频的链接,点击后跳转到了PP视频主页,作为体育爱好者,在体育频道中找到了相关的新浪微博的内容,再次点击后又来到微博的页面继续阅读,从而形成了一条路径。如果把所有的可能路径呈现出来,就会看到一个网络结构。
网络爬虫模拟了人们浏览网页的行为,只是用程序代替了人类的操作,在广度和深度上遍历网页。如果把互联网上的网页或网站理解为一个个节点,大量的网页或网站通过超链接形成网状结构。爬虫通过遍历网页上的链接,从一个节点跳转到下一个节点,就像是在一张巨大的网上爬行,但是比人类的速度更快,跳转的节点更全面,所以被形象地称为网络爬虫或网络蜘蛛。
二、爬虫的发展历史
网络爬虫最早的用途是服务于搜索引擎的数据收集,而现代意义上的搜索引擎的鼻祖是1990年由加拿大麦吉尔大学(University of McGill)学生Alan Emtage发明的的Archie。
人们使用FTP服务器共享交流资源,大量的文件散布在各个FTP主机上,查询起来非常不方便。因此,他开发了一个可以按照文件名查找文件的系统,能定期搜集并分析FTP服务器上的文件名信息,自动索引这些文件。工作原理与现在的搜索引擎已经非常接近,依靠脚本程序自动搜索分散在各处FTP主机中的文件,然后对有关信息进行索引,供使用者以一定的表达式查询。
世界上第一个网络爬虫“互联网漫游者”(“www wanderer”)是由麻省理工学院(MIT)的学生马休·格雷(Matthew Gray)在 1993 年写成。刚开始,它只用来统计互联网上的服务器数量,后来则发展为能够通过它检索网站域名。
随着互联网的迅速发展,使得检索所有新出现的网页变得越来越困难,因此,在“互联网漫游者”基础上,一些编程者将传统的“蜘蛛”程序工作原理作了些改进。其设想是,既然所有网页都可能有连向其他网站的链接,那么从跟踪一个网站的链接开始,就有可能检索整个互联网。
其后,无数的搜索引擎促使了爬虫越写越复杂,并逐渐向多策略、负载均衡及大规模增量抓取等方向发展。爬虫的工作成果是搜索引擎能够遍历链接的网页,甚至被删除的网页也可以通过“网页快照”的功能访问。
三、网络爬虫的礼仪
礼仪一:robots.txt文件
每个行业都有其Code of Conduct,成为行为准则或行为规范。比如,你是某个协会中的成员,那就必须遵守这个协会的行为准则,破坏了行为准则是要被踢出去的。
最简单的例子,你加入的很多微信群,一般群主都会要求不可以私自发广告,如果未经允许发了广告,会被立刻踢出群,但是发红包就没事,这就是行为准则。
爬虫也有行为准则。早在1994年,搜索引擎技术刚刚兴起。那时的初创搜索引擎公司,比如AltaVista和DogPile,通过爬虫技术来采集整个互联网的资源,与Yahoo这样的资源分类网站激烈竞争。随着互联网搜索规模的增长,爬虫收集信息的能力快速进化,网站开始考虑对于搜索引擎爬取信息做出限制,于是robots.txt应运而生,成为爬虫界的“君子协定”。
robots.txt文件是业内惯用做法,不是强制性的约束。robots.txt的形式如下:
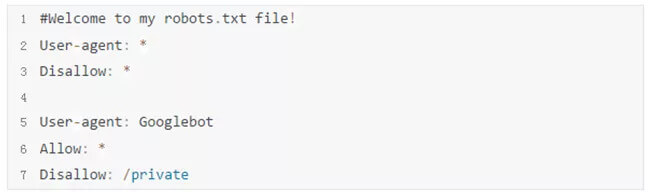
在上面这个robots.txt例子中,所有的爬虫都被禁止访问网站的任意内容。但是Google的爬虫机器人,可以访问除了private位置的所有内容。如果一个网站上没有robots.txt,是被认为默许爬虫爬取所有信息。如果robots.txt做了访问的限制,但是爬虫却没有遵守,那就不是技术实现这么简单的事情了。
礼仪二:爬取吞吐量的控制
曾经出现假冒Google搜索引擎的爬虫去对网站进行DDoS攻击,让网站瘫痪的事情。近年来,恶意爬虫造成的DDoS攻击行为有增无减,给大数据行业蒙上了爬虫的阴影。因为其背后的恶意攻击者,往往具备更为复杂和专业的技术,能绕过各种防御机制,让防范这样攻击行为难上加难。
礼仪三:做一个优雅的爬虫
优雅的爬虫背后,一定站着一个文明人或者一个文明团队。他们会考虑自己写的爬虫程序是否符合robots.txt协议,是否会对被爬网站的性能造成影响,如何才能不侵害知识产权所有者的权益以及非常重要的个人隐私数据等问题。
出于能力的差别,并不是每个爬虫团队都能考虑到这些问题。2018年,欧盟出台的《General Data Protection Regulation》(通用数据保护条例)中对数据的保护做出了严格的说明。2019年5月28日,国家互联网信息办公室发布的《数据安全管理办法》(征求意见稿)对爬虫和个人信息安全做出了非常严格的规定。比如:
(1)第十六条 网络运营者采取自动化手段访问收集网站数据,不得妨碍网站正常运行;此类行为严重影响网站运行,如自动化访问收集流量超过网站日均流量三分之一,网站要求停止自动化访问收集时,应当停止。
(2)第二十七条 网络运营者向他人提供个人信息前,应当评估可能带来的安全风险,并征得个人信息主体同意。
其实,我国2017年6月1日施行的《中华人民共和国网络安全法》第四章第四十一条和四十四条就已经对个人隐私信息数据的收集和使用做出明文规定,这也与爬虫直接相关。


法律制度的出台,给技术的边界做出了明确的限定,技术无罪并不能作为技术实施者为自己开脱的理由。爬虫在实现自己需求的同时,必须做到严格遵守行为准则和法律条例。
四、各类反爬虫技术介绍
为了保护自己合法权益不被恶意侵害,不少网站和应用APP应用了大量的反爬技术。这使得爬虫技术中又衍生出反反爬虫技术,比如各类滑动拼图、文字点选、图标点选等验证码的破解,它们相互促进、相互发展、相互伤害着。
反爬虫的关键在于阻止被爬虫批量爬取网站内容,反爬虫技术的核心在于不断变更规则,变换各类验证手段。
这类技术的发展甚至让人痴迷,比DOTA对战还让人热血沸腾。从那晃动如波浪的文字验证码图形的伪装色里彷佛都能看得见程序员的头发。
1、图片/Flash
这是比较常见的反爬手段,将关键数据转为图片,并添加上水印,即使使用了OCR(Optical Character Recognition,文字识别)也无法识别出来,让爬虫端获取了图片也得不到信息。早期一些电商的价格标签中经常见到这种方式。
2、JavaScript混淆技术
这是爬虫程序员遇到最多的一种反爬方式,简单来说其实就是一种障眼法,本质上还是一种加密技术。很多网页中的数据是使用JavaScript程序来动态加载的,爬虫在抓取这样的网页数据时,需要了解网页是如何加载该数据的,这个过程被称为逆向工程。为了防止被逆向工程,就用到JavaScript混淆技术,加JavaScript代码进行加密,让别人看不懂。不过这种方式属于比较简单的反爬方式,属于爬虫工程师练级的初级阶段。
3、验证码
验证码是一种区分用户是计算机还是人的公共全自动程序,也是我们经常遇到的一种网站访问验证方式,主要分为以下几种:
(1)输入式验证码
这是最最常见的,通过用户输入图片中的字母、数字、汉子等字符进行验证。
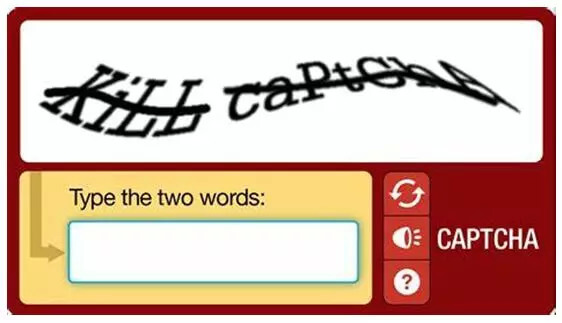
图中CAPTCHA 的全名是(Completely Automated Public Turing test to tell Computers and Humans Apart),中文翻译为:全自动区分计算机与人类的图灵测试。实现的方式很简单,就是问一个电脑答不出来但人类答得出来的问题。不过,现在的爬虫往往会用深度学习技术对这样的验证码进行破解,这样的图灵测试已经失效。
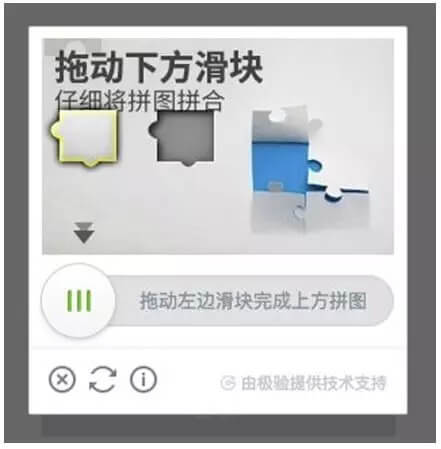
(2)滑块式验证码
鉴于输入式的图形验证码的缺点,容易被破解,而且有时候人类都识别不了。滑块验证码横空出世,这种验证码操作简便,破解难度大,很快就流行起来了。破解滑块验证码存在两大难点:一是必须知道图形缺口在哪里,也就是得知道滑块滑到哪;二是要模仿出人类滑动的手势。这样的验证码增加了一定的难度,也给爬虫界增加了很多乐趣,一时间大量破解滑块验证码的技术出现。
(3)点击式的图文验证和图标选择
图文验证,是通过文字提醒用户点击图中相同字的位置进行验证。

图标选择,是给出一组图片,按要求点击其中一张或者多张。

这两种原理相似,只不过是一个给出文字,点击图片中的文字;一个给出图片,点出符合内容的图片。这两种方法的共同点就是体验差,被广为诟病。
(4)手机验证码
对于一些重要的敏感信息访问,网站或APP端一般会提供填写手机验证码的要求,通过手机接受网站发送的验证码来进一步访问,这种方式对于数据隐私的保护比较好。
4、账号密码登陆
网站可以通过账号登陆来限制爬虫的访问权限,个人在使用很多网站服务的时候一般是需要进行账号注册的,使用的时候需要通过账号密码登陆才能继续使用服务。网站可以利用用户浏览器的Cookie来对用户的身份进行识别,通过保存在用户本地浏览器中加密的Cookie数据来进行用户访问会话的跟踪。这一般作为前面几种反爬方式的补充。
五、爬虫技术的发展方向
传统网络爬虫最大的应用场景是搜索引擎,普通的企业更多是做网站或应用。后来随着网络数据分析的需要,以及互联网上的舆情事件层出不穷,针对网络爬虫有了大量的需求,采集的对象主要是些新闻资讯。
近些年,由于大数据处理和数据挖掘技术的发展,数据资产价值的概念深入人心,爬虫技术得到更加广泛和深入的发展,采集对象也更丰富,高性能、并发式的技术指标也更高。
围绕网络爬虫合法性的讨论仍然存在,情况也比较复杂。目前的趋势下,许多法律问题还处于模糊地带,往往取决于具体的案例影响。然而,可以肯定的是,只要有互联网,就会有网络爬虫。只有网络爬虫让体量巨大的互联网变得可以搜索,使爆炸式增长的互联网变得更加容易访问和获取,在可预见的未来,互联网爬虫技术将继续得到发展。
互联网作为人类历史最大的知识仓库,是非结构化或非标准化的。互联网上聚集了大量的文本、图片、多媒体等数据,内容虽然非常有价值,但是知识提取的难度仍然非常巨大。语义互联网、知识共享等概念越来越普及,真正语义上的互联网将是网络爬虫的目标。此外,物联网技术的发展,将是互联网的升级形式,也将是爬虫技术未来发展的方向。
(本文由公众号“苏宁财富资讯”原创,作者为苏宁金融研究院金融科技研究中心副主任沈春泽、研究员李加庆)
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号