本文共字,预计阅读时间。
文/长江证券信息技术总部陈传鹏、赵文龙、舒小奎、董理骅
(本文为“证券机构数字化转型与证券科技创新”征文活动精选文章。)
一、研究背景
随着信息技术飞速发展,人工智能、大数据、区块链等技术的广泛应用,金融科技浪潮引发了数据量迅猛增长。数字化转型、数字化新生态,对数据服务提出了灵活敏捷、智能高效的要求。面对需求紧急繁杂、数据来源异构、服务方式多样等数据服务的固有难点,构建灵活、开放的技术架构,提升快速准确响应需求能力,提供高效安全的数据服务,成为数据敏捷服务的关键。
数字化转型、数字化新生态,数据是流动的基本要素。机械化解放了人类的肢体,信息化改变了人类的生产生活方式,第四次工业革命,有说智能革命也有说生物科技,但数字化将在虚拟空间重塑现实时空、人工智能下,人类的思维模式也许将会被颠覆。为什么中美贸易战无时无刻不在争夺5G的高地,因为5G是基础,与物联网+云计算+区块链将构建数字时空的基础设施,是百年未有之大变局,是新旧动能转换的驱动力,数据智能与敏捷服务将是数字化时空的生产资源和生产力,无数据不智能、不敏捷无服务已成为共识。
1.1 国际大数据技术发展概述
在大数据发展的初期,技术方案主要聚焦于解决数据“大”的问题,Apache Hadoop 定义了最基础的分布式批处理架构,打破了传统数据库一体 化的模式,将计算与存储分离,聚焦于解决海量数据的低成本存储与规模化处理。Hadoop凭借其友好的技术生态和扩展性优势,一度对传统大规模并行处理(massively parallel processor, MPP)数据库的市场造成影响[1]。
MapReduce暴露的处理效率问题以及Hadoop体系庞大复杂的运维操作,推动计算框架不断进行着升级演进。随后出现的Apache Spark已逐步成为计算框架的事实标准。在解决了数据“大”的问题后,数据分析时效性的需求愈发突出,Apache Flink、Kafka Streams、Spark Structured Streaming等近年来备受关注的产品为流处理的基础框架打下了基础[2]。在此基础上,大数据技术产品不断分层细化,在开源社区形成了丰富的技术栈,覆盖存储、计算、分析、集成、管理、运维等各个方面。
1.2 大数据在金融行业应用发展概述
大数据应用提升金融行业运转效率,实现金融业在数据资产管理、运营管理、客户服务等方面应用效果已经取得较大共识。一方面可以推动金融机构业务驱动模式的转型,另一方面通过大数据技术产品的应用迭代和创新发展,新产品和新服务不断发展,而机构可以通过投资或合作,与新兴金融科技公司形成业务互补,进一步推动技术创新再金融行业的应用。
在大数据应用初始阶段,结合线上系统和业务系统的落地数据,利用互联网和移动设备为客户提供线上自助式服务。通过大数据分析,优化产品界面,简化业务流程,适用于所有金融行业,并在实践中取得良好应用效果。在此阶段,大数据技术的主要应用是数据架构与信息整合,主要功能是简单的分析与初步决策并且构建一个存储信息的的大数据系统。
目前大数据已经发展到处理分析大量终端用户数据的阶段,为金融公司提供了良好的数据基础。例如大数据分析在金融领域应用的一个典型主要在个人征信、授信与风险管控,覆盖贷前评估、贷中监控与贷后反馈等环节。云计算与大数据的爆发式发展则为人工智能提供了技术基础,人工智能主要体现在智能数据分析与决策。如果将人工智能拆分为基础层、技术层和应用层三个层面,那么在基础层面,细分技术如大数据的发展不可或缺;在技术层面,与大数据最相关的是知识图谱、机器学习与自然语言处理等;在应用层面,主要包括神经网络、遗传算法与AlphaGo等[3]。
1.3 大数据证券行业应用痛点分析
面对源系统来源多样、业务规则灵活多变、数据监管要求日渐趋严、数据人力资源相对短缺等现实问题。大数据证券行业应用的痛点,我们都曾经历或正在经历。数据之繁乱,即便同类业务在不同时期的数据格式也都相互不兼容。理想和现实的差距,我们都曾觉得ABCD可以无所不能,我们都想有商业化的大数据平台,屏蔽底层复杂的技术栈,但同时黑盒封装又导致架构失去了灵活性,无法适配更多的业务场景,更难以匹配大数据技术发展的速度。不同商业化产品,因其架构和开发框架差异,IT部门不得不配备多个团队来支持不同平台的开发和运维,数据团队的包袱越来越重。数据工程师的要求也越来越高,既要懂业务、又要懂技术、还要懂算法,“会听”即理解业务需求、“会说”、“会写”和“会画”即数据可视化效果要酷炫,可还是无法完全满足业务部门的多样化需求,理想中的大数据好像变成了IT部门沉重的包袱。
本研究运用现有大数据平台技术基于模块解耦、架构开放、可集成等特性,通过自由拆分、灵活组合来提供敏捷高效的数据服务。
二、敏捷大数据构建关键技术及内容研究
2.1 敏捷大数据构建方法论
敏捷大数据服务方法论,是基于通用平台工具组合构建底层数据服务基础,在此基础上实现数据安全及运维,结合通用技术平台和数据服务方法,实现多种场景数据敏捷服务实践能力。
基于敏捷服务的基本方法和模型,本研究的关键技术在于构建数据服务基础和实现构建敏捷数据服务能力两方面。在构建数据服务基础层面,应用数据全生命周期方法,根据数据离线服务和在线实时服务的不同技术诉求,关键技术在于构建解耦、开放、灵活、复用的技术框架。在数据敏捷服务层面,为能够融通专业团队与平台工具,数据智能和敏捷服务、贯通业务与技术系统,关键在于将数据团队进行合理的技术划分,数据团队形成各自专精业务技术能力栈,同时构建小组间高效数据交换规范。敏捷数据服务的基本方法和模型如图1所示。

图 1 敏捷大数据服务方法论
通过能力栈与技术栈结合,构建安全稳定、灵活拆分、自由组合的数据服务乐高桥,同时平台架构可集成、可配置和可管控,保障敏捷大数据服务的安全稳定,形成模块化、模式化、模板化的数据敏捷服务。敏捷的服务目标,首先技术栈要实现数据智能,其次能力栈提供敏捷服务。
2.2 构建敏捷大数据技术栈
在技术栈方面,通过对采集、存储、计算、服务四个方面架构解耦,形成4个核心技术栈近30个技术平台和模块,同时满足接口开放,支持模块化灵活组合要求,支持统一管控,保证场景模板的状态要可持续监控、管理、控制。技术栈数据智能的技术框架如图2所示。

图 2 数据基础技术栈技术框架图
针对不同的数据源和应用场景分别使用DataStage或Kettle两种ETL工具来实现离线数据的采集。在目前关系型数据库为主的应用场景下准实时(秒级)数据库同步通过DSG实现,对于某些特殊数据源应用不同的高级语言定制开发实现数据的自动化采集。通过对关系型数据库数据的抽取,日志收集服务器对移动应用APP和页面埋点数据的采集、对日志文件的传输和接收以及实时数据流的采集,将源数据存储到分布式文件系统、大数据数据仓库、消息队列、搜索引擎和内存数据库等存储系统中,然后通过大数据离线计算框架和实时计算框架对数据同时进行处理,以API和OLAP等形式提供数据服务,最终于应用APP和BI报表等多种方式呈现和展示数据。
2.3 构建敏捷大数据能力栈
基于解耦的采集、存储、计算、服务四个技术栈,对应的划分相应的采集、计算与服务数据小组。一方面,各个小组深入研究各技术栈细节并提供敏捷的技术服务能力,另一方面,各个小组间形成高效数据交换规范,针对不同的数据需求,各自选择采集、存储、计算、服务技术栈里最优的模块,通过协同作战模式快速响应需求。敏捷数据服务平台要支持多种应用场景,如营销活动的突发事件需求,适配Devops敏捷开发的持续迭代型,以及技术驱动的特征工程。
(1)数据交换方面,大批量的离线数据库同步DateStage,多源异构间的数据交换。结构化数据库通过DSG推送到实时数据总线Kafka,通过Flinkx实现任意数据源类型的数据同步。日志和文件采集工具Logstash,实时数据流Stream采集使用Flume,定向的Web数据通过Scrapy爬虫抓取。
(2)计算方面:针对结构化数据库,支持存储过程,Spark的离线任务或流式的实时Flink计算。
(3)服务方面,对于日志类搜索分析,采用ES或Splunk架构,多为数据关联分析Kylin,量化工程师,提供SDK组件,营销服务人员FineReport、监控告警Grafana、搜索查询可视化Kibana、营销活动统计Davinci。此外,对接系统方面,提供了Restful-API,以及量化SDK-jar/py服务。
2.4 构建典型实时和离线数据服务框架
基于技术栈和能力栈的组合,我们把敏捷数据服务抽象出两个通用的数据应用场景:
(1)敏捷数据服务之典型实时数据应用
实时数据应用可以分为数据采集,数据交换,数据计算,数据服务4个模块,数据采集方面,通过成熟的DataStage支持关系型数据库的批量采集,通过Flinkx支持非关系型数据库的数据采集。根据数据量和业务需求,将数据存储在传统关系型数据库或者统一发送到Kafka消息队列中,然后通过Flink进行实时计算,计算结果输出到不通的关系型数据库或者NoSQL数据库中,然后通过Presto或者Kylin提供即时查询服务,Presto分布式SQL查询引擎,用于支持高速实时的数据分析,Kylin基于SQL查询接口及多维分析能力支持超大规模数据。整个实时计算的技术实现框架及原理如图3所示。
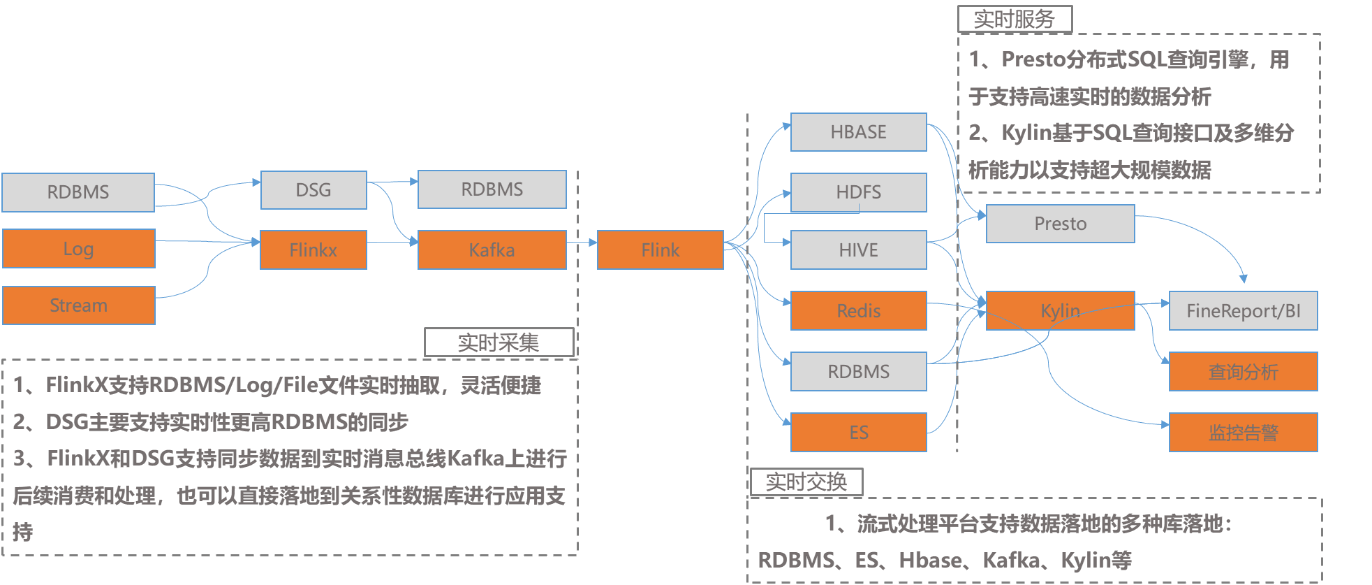
图 3 实时计算方案技术实现框架
(2)敏捷数据服务之典型离线数据应用
离线数据应用同样可以解耦为采集、存储、计算、服务四个模块。在采集方面,通过成熟的DataStage支持关系型数据库的批量采集,通过Flinkx支持非关系型数据库的数据采集。根据数据量和业务需求,将数据存储在传统关系型数据库或分布式NoSQL数据库中。根据数据仓库分层思想,对数据进行预处理计算和再加工计算,形成不同主题域数据集,对数据进行特征因子构建,通过标签规划、业务规则和模型算法,形成数据指标,持久化到数据服务层,对外提供丰富、准确的数据服务。完整离线数据应用框架见图4。
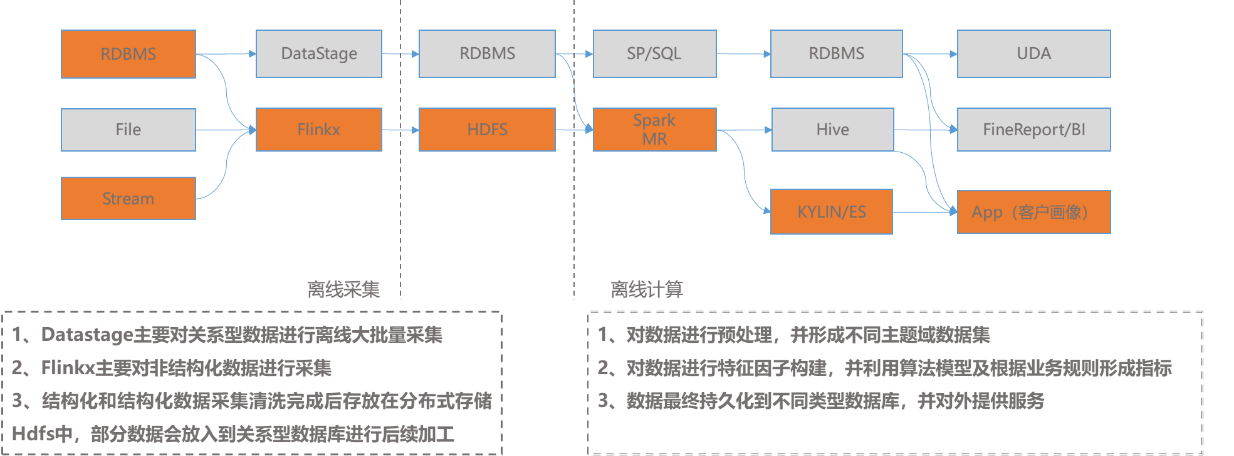
图 4 离线数据应用技术框架
本研究在研究过程中发现团队赋能平台、技术融合业务,让技术栈和能力栈真正复用,才能变加法为乘法。团队专业化分工,由数据需求工程师对接产品经理承接业务需求,通过团队协作形成敏捷的数据服务模板:实时数据计算、分布式批处理、搜索查询服务、数据多维关联分析、内存实时数据交互。此外,每个工程师在具备专业技术能力基础上,同时深度掌控某个业务领域知识,充分提升数据工程师的个人价值,实现双赢。
本文的研究内容概括为基于技术栈、能力栈,团队能力实现模块化、模式化和模板化的灵活组合,形成可集成、可配置和可管控的大数据平台,通过自由拆分与灵活组合,再融入灵活机动、专业化分工的采集、计算、服务数据工程师,实现数据智能和敏捷服务。
三、敏捷大数据平台的行业应用
基于技术栈灵活支持,能力栈敏捷服务的目标,通过构建完成统一数据处理平台,实现平台管理包含元数据,调度,监控,权限统一管理集成,基于不同的数据源支持多种ETL工具和开发语言实现数据加工处理,提供数据API及SDK平台。针对智能投研、多业务线条数据服务支持、监管机构风险评估等数据服务方面,实现数据快速响应、敏捷服务的数据应用能力。
3.1 运营管理复合数据服务应用
随着公司发展,公司领导在管理公司过程中,十分重视风险管理这项证券公司核心的竞争力,但是发现资产类数据繁多,没有全面的资产视图,就无法从中发现可能存在的风险点。通过对各个业务部门、子公司、孙公司的各项表内表外资产的分析,理清出每一项资产的底层业务,基于敏捷大数据服务能力,通过全方位、可视化、多场景、准确、及时地展示经营、风控、财务、产品运营等数据。通过构建多维多屏驾驶舱实现明确经营方向、降低经营风险、开源节流以及优化产品设计构建多维多屏数据驾驶舱等内容,支撑公司成为以数据为驱动的企业。
多业务线条主要在公司风险管理、客户服务、业务运营等多方面提供支持。面向公司领导层、风险管理部、财务总部、人力资源部等部门,通过公司驾驶舱、财务日报、经纪业务驾驶舱、子公司驾驶舱等数据产品,全面展示和监控公司的整体风险情况(净资本、净资产、风险敞口、流动资产储备、业务规模、损益等指标)、各自营部门风险情况(净值、持仓、风险评分、VaR值、HHI等指标)、市场情况(股、债、货币、外市);公司成本、支出、利润情况;各业务条线成本、利润、利润因子;投资业务持仓、收益情况;流动性管理相关指标;子公司业务数据、财务数据以及风控相关数据。
通过累计多次的产品迭代,通过对驾驶舱的数据支持,已经涵盖了财务、风控、人力等业务条线信息,完成对集团公司包括子公司的全面数据覆盖。在数据时效性方面,数据更新频率从最开始建立时的季度报告,更新为月度报告,财务日报更新频率为日更新,及时准确反映公司运营情况。在数据适用性方面,驾驶舱产品已经全面兼容大屏、手机版、PC版,实现全场景数据可视化应用。
3.2 风险管理数据应用
异常交易的风险监控是行业监管科技的重点,是证券经营机构的一项持续性工作。但异常交易需求极具不确定性,因其一是偶发性受市场、人员、技术因素营销等,极具不确定性。二是隐蔽性,场外配资、账号出借、代客理财等等,场景多、无法一一枚举,三是多变性,2015-homs伞形账户,可能更多是场外配资,或者是虚拟盘诈骗;四是时效性,震荡市、单边上涨、单边下跌的异常交易行为差异等等,我们很难定义一个统一、标准和准确的异常交易模型。异常交易是一个需要业务和技术协同、在实践中总结归纳、持续完善的过程。异常交易监检测业务技术协同机制如图5所示。
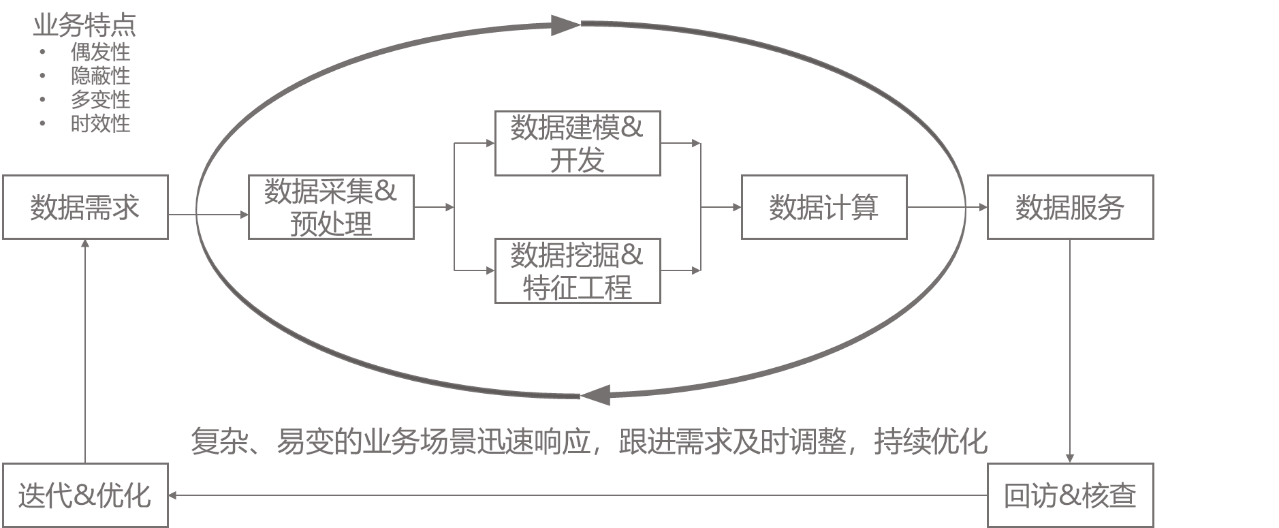
图 5 异常交易监测业务技术协同机制
敏捷的业务需求中,首先快速响应,从交易行为出发,通过Flinkx快速同步结构化数据到HDFS大数据平台,并按业务沟通结果,根据资金量、持股数量多、交易频繁、资金异常等多个特征指标,最关键的是根据特征指标对公司所有客户建模筛选出与众不同的的少数疑似客户,通过FineReport报表每月提交业务部门进行核查。异常交易特征指标处理方案见图6。
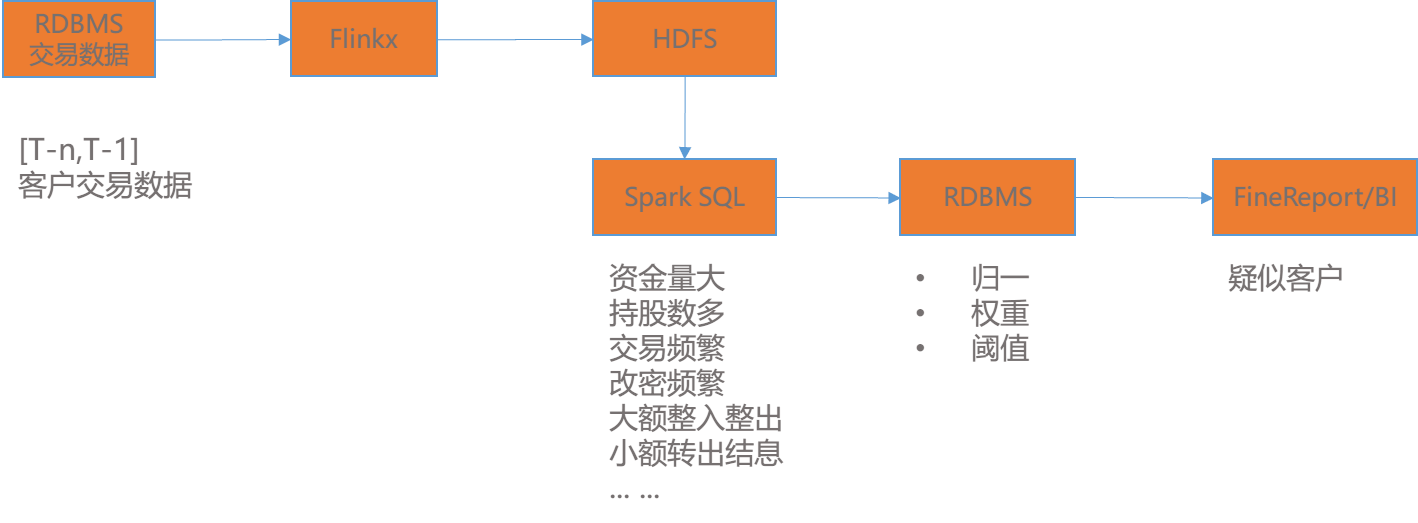
图 6 异常交易特征指标数据处理方案
根据业务部门实际回访、以及数据工程师的特征工程,对异常交易监测模型持续完善。我们加入了埋点行为、网络流量实时数据,同增加实时计算的特征指标进行筛查。
离线异常交易指标中,引入了云主机+高龄,引入员工APP与客户APP碰撞模型,以及普通、信用账号、交易、申购分离,以及申购获利了结,包括中证信息近期的客户端安全升级,客户使用等外挂数据。
实时异常交易指标中,我们将埋点行为数据通过Flume经Flinkx到Kafka实时消息总线,互联网服务实时网络流量通过Logstash采集,Flink实时窗口计算来发现短时多设备操作异常,多IP的异地登陆或委托异常,埋点高频点击异常和路径异常。同时结合网络流量实时计算异常模型,发现黑IP和黑终端情报,实时异常交易特征指标数据处理方案见图7。
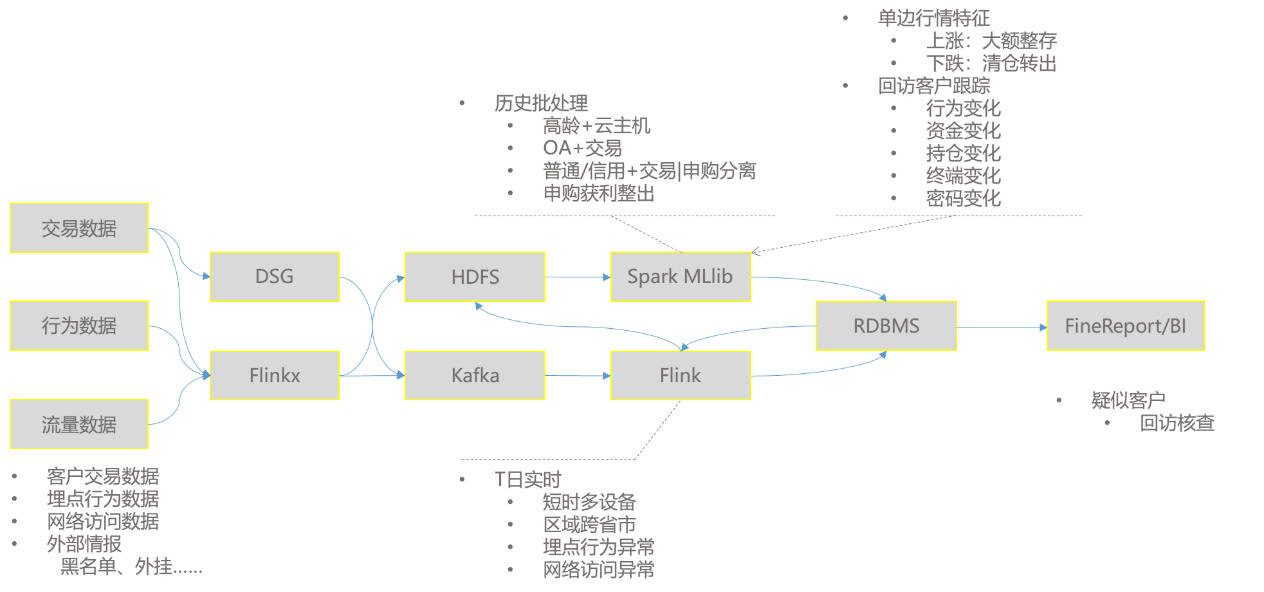
图7异常交易特征指标数据处理方案
针对疑似客户的报表更为及时和丰富,由月度更新到实时更新,包含的行为异常的时间、地点、异常操作原因。疑似客户的结果数据存入关系型数据库,可以用于结合行情进行趋势分析、以及异常客户的持续周期。在实际日常交易行为中,本方案有效并且及时的发出疑似异常交易客户预警,发送给业务部门进行回访核查,监测效果得到业务部门充分肯定。
3.3 客户服务数据应用
L2产品双11活动,是数据典型应用的业务营销场景。客户营销类需求紧急,持续时间短,线上的临时数据统计任务多。我们配合业务线全程参与,活动启动,与H5开发设计埋点,包括点击埋点、停留时长、访问路径等,针对性设计营销指标和模型。推广阶段,H5测试上线,配套的数据采集、计算、报表支持,这些都是搭积木式的组合,埋点有现成的规范、采集和存储,计算有现成通用平台,报表可视化也是业务熟悉的通用化平台,支持在线的指标测试、模型验证,双11正式上线,实时的营销策略优化支持。
通过用户地图构建用户热力图和漏斗模型,发现用户兴趣点和流失节点,从而优化营销活动设计。并根据用户转化情况,适时进行用户提醒,调整营销策略。通过营销业绩渠道归因,评估营销渠道引流效果和客户质量,辅助营销渠道选择。建立基于交易数据和行为数据的客户偏好模型,利用该模型,全面反映客户最新兴趣点,进行潜在客户挖掘,开展精准营销。整个营销活动数据敏捷支持流程如图8所示。
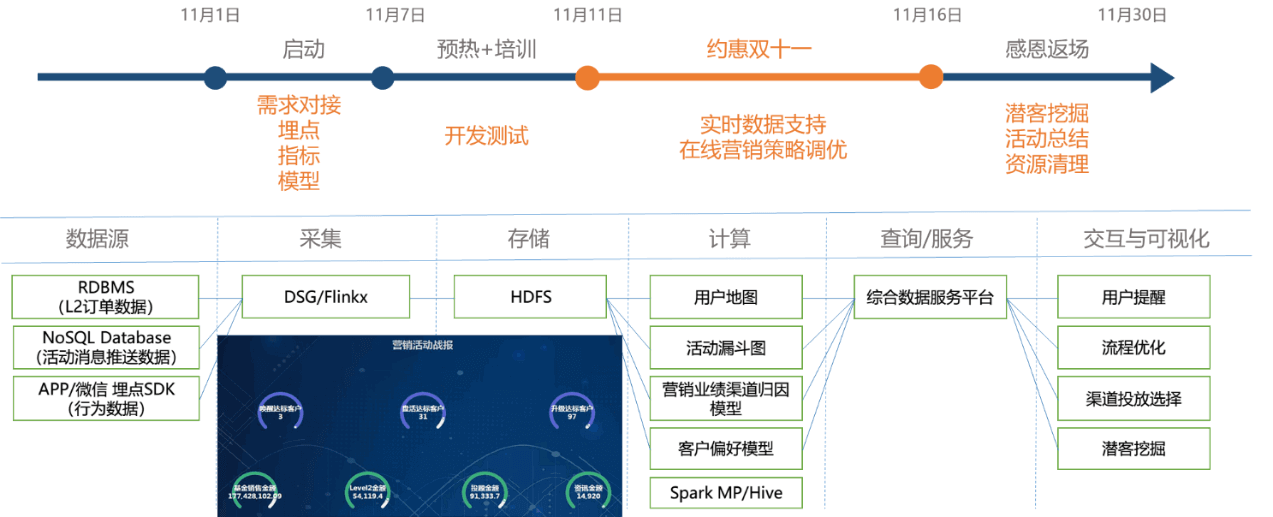
图 8 双11营销活动数据敏捷支持流程
在进行相关数据支持后,充分降低了营销成本,提升了营销效果,单次活动实现百万级销售营收。
四、总结
构建整套敏捷数据服务技术栈,涵盖数据采集,数据存储、数据计算、数据分析、数据交互和可视化等方面,灵活拆分的基础构件,实现模块化、模式化和模板化的灵活组合,实现开放解耦、高效敏捷、灵活复用的数据服务。
研究敏捷大数据技术栈,我们并没有抛弃传统数据仓库,一方面,业务功能历史遗留,迁移需要时间和代价,以及某些核心交易类业务数据需求,通过传统的SP/SQL存储过程实现更为便捷,效率也不低。另一方面,大数据平台架构的输出结果,在对接现有App应用层时,通过数据仓库的数据集市进行缓存,避免在大数据集群服务故障时,保障前端应用的高可用。数据仓库作为大数据平台到应用服务间的缓冲垫,降低数据服务中断风险。模块化、模式化和模板化,有优点,也有缺点。优点是灵活拆分、自由组合,敏捷响应,但缺点也很明显,组合的解决方案不一定是最优的。
本研究基于通用平台工具组合构建大数据引擎,以数据团队为能力支撑,应用数据全生命周期方法,提供便捷、高效、灵活、丰富、更快迭代的敏捷数据服务。
参考文献
[1]孙会峰. 2019中国大数据产业发展白皮书[J]. 互联网经济, 2019(Z2).
[2]中国信息通信研究院. 大数据白皮书(2019)[EB/OL].[2019-12].http://www.caict.ac.cn/kxyj/qwfb/bps/201912/t20191210_271280.htm.
[3]吴之悦, 顾诚嘉. 大数据金融与Fintech发展的技术基础[J]. 现代商业, 2018, 000(013):31-32.
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号