本文共字,预计阅读时间。
文/上海东方证券资产管理有限公司林杰、罗燕斌、张洁佩
(本文为“证券机构数字化转型与证券科技创新”征文活动入围文章。)
一、传统资管与数字化资管
自2008年金融危机以来,全球在管资产保有量从38万亿美元翻倍超过80万亿美元,全球资产管理行业正处在一个结构性增长的旺盛期。而中国资产管理行业迅速崛起正是支撑全球资产管理市场快速爆发的主要因素之一。
从全球资管发展趋势来看,无论是世界老牌资管机构贝莱德早从2000年起就投入研发并不断迭代演化的Aladdin系统(为其发展起到了举足轻重的作用);还是摩根大通强制要求新进资产管理分析师熟悉编程语言和算法分析;以及近期国内各家金融企业披露的关于2019年金融科技投入与科技人员数据,都反映出国内外资管企业期望通过金融科技的应用拓宽自己的投资能力、投资范围,提升效率,提高准确率,尽可能提高投资回报率。
在DT时代的数字化浪潮下,通过企业数字化转型,挖掘金融科技的切入点,是目前多数传统资管业务探求新增长爆发点的主要途径。以数据为本,通过业务驱动,促使传统资管向数字化资管转型逐步迈进。
例如:原本依靠专业人士的分析和判断、主观性和情绪化较强的投研领域,通过数字化转型实现囊括智能资讯和投研大数据的智能投研平台,并构建多维度、多策略投资组合,以高性能量化交易来提高投资效率;亦或是原本大多依靠主观分析判断,设置有限的量化指标进行的风险管理,通过数字化转型实现多维度量化指标数据的系统化、可视化,并且以实时在线的方式进行动态监控;又或是在客户服务领域,通过数字化转型帮助企业进行智能KYC、智能资产配置,并以线上化、移动化为载体,通过远程视频、AI智能机器人等手段,改变以往客户服务大多以线下网点为核心,供需信息不匹配的情况;以及属于资管业务中后台的运营管理领域,借助数据统一管理,以线上线下协调运营的模式,改善传统资管运营中产品和账户等信息分散隔离、人工搬运、流程繁琐冗杂的情况,真正实现自动化运营,智能化管理。
二、从数字化转型到数据生态建设
近年来,无论是互联网新兴行业,还是传统制造行业,都在积极响应国家发展数字经济的号召,将企业数字化转型作为重要发展战略。企业要进行数字化转型,数据建设是重要基础和必要条件。而完整的数据建设,不单是数据的存储和使用,更需要构建完整的数据生态,主要涉及以下五个方面:
1、数据汇聚:加强数据的采集,实现结构化数据和非结构化数据的积累,自动加工,通过技术实现多元异构数据的积累和汇聚。
2、数据共享:打通内部数据孤岛,集成数据接口,统一提供数据,提高数据的价值和使用范围。
3、数据应用:扩大数据应用场景,提升数据分析的效率,从业务出发,探索数据的潜在价值,充分发挥其主观能动性。
4、数据治理:数据质量关乎数据的产出是否有效,完善的数据治理能够提升数据运维效率,避免数据问题,降低数据风险,控制审查数据工作。
5、数据安全:互联网时代在提供便利的同时也产生诸多隐患,数据安全关乎每个人,数据泄露,不仅造成企业损失,更会造成投资者的损失。
由此可见,在企业数字化转型、企业数据建设过程中,需从这五个方面进行详细的思考和规划从而提升企业数据建设的效率和完整性,降低风险发生概率,便于运维和开发人员排查、解决、验证问题,为企业的业务发展提供更强大的助力。
三、数据血缘梳理
企业数据生态建设是一个复杂的长期工程,本文将从数据生态建设过程中数据治理部分入手,重点分析如何通过数据血缘梳理实现资管业务数据质量的大幅提升。
根据国际数据管理协会(DAMA)给出的定义:数据治理是对数据资产管理行使权力和控制的活动集合,其并不是一个简单的行为动作,而是一个形成体系的管理。数据治理是数据生态中非常重要的一环,它关系到数据的准确性、可用性,深刻影响数据的后续使用。如果不能保证数据的标准和质量,那么数据产出结果将无法得到保证,进而会影响使用者的分析和判断,一旦得出错误的结论,轻则做无用功,重则造成巨大的损失。
以2020年5月9日中国银保监会发布9张罚单为例,其中8张是针对国有六大行和2家股份制银行因监管标准化数据(EAST)系统因数据质量及报送存在违法违规行为开具,相关罚款金融共1770万元。由于数据质量问题导致披露信息错误不仅损害公司的声誉,同时也切实损害了客户权益。
不仅是银保监会对银行等金融机构有比较严格的监管,证监会于2019年6月颁布《证券基金经营机构信息技术管理办法》,在管理办法中对证券基金机构提出数据治理要求,要求机构设立信息技术治理委员会对数据治理进行规划,履行数据安全及数据质量管理职责。由此可见,数据治理是一个必要的公司规划,环环相扣。
在实际的生产环境中,常常发现数据的问题比较复杂,从初始的数据标准制定、中间环节的数据集成、数据处理,到最后的数据应用,任何环节出错都可能导致数据质量问题。因此,解决数据质量和规范数据口径需从源头和管理着手。
数据治理可从多重维度、多元主体、多种手段推进,不仅是技术人员工作职责,更是业务部门、决策层的管理职责。本文从公司信息技术团队的角度,详细讲解技术层面实现数据治理的部分工作。
由此本文引进数据血缘的概念。通过数据血缘技术实现数据的溯源追踪,帮助完善数据治理和运维优化。
(一)数据血缘介绍
数据血缘是指数据与数据之间形成的多重关系,它记载着数据处理的整个周期,包括数据的来源起点,数据的处理汇总,数据的后续应用等,在数据分析、数据挖掘、数据预测、数据质量控制、数据可用性方面有着至关重要的意义。数据血缘关系有如下四个应用场景:
1、数据溯源
通常企业进行分析处理的数据,来源非常广泛,有可能来自内部系统,如投资交易数据、估值数据、登记过户数据;也可能来自外部环境,如互联网公开数据,或是通过数据采购从第三方获取的数据。不同的数据来源,其质量层次不齐,对分析处理结果的影响也不尽相同。当数据发生异常时,需能追本溯源,实现风险可控管理。
数据血缘关系,正是体现数据的来龙去脉,帮助追踪数据来源以及数据处理过程。数据来源节点关联转换可以一目了然的通过可视化动态图展现出来,实现对异常数据原因溯源分析。
2、评估数据价值
数据血缘关系能够直观的展现数据的价值:
1)数据使用广度:通过数据血缘关系形成的数据关系图,可以直观展现数据使用范围,使用范围越多,说明数据的价值越大。
2)数据更新量级:在数据血缘关系图中,数据流转线路的线条越粗,表示数据更新量级越大,同时侧面反映数据价值的大小。
3)数据更新频率:数据更新频率越高,表示数据时效性越强,数据越鲜活,则价值越高
3、评估数据质量
从数据血缘关系图上,可以直观看到清晰的数据标准清单,也从另一个侧面反映对数据质量的要求。
4、数据归档/销毁的参考
在数据关系图上,当某个数据没有了受众,不再被其他对象使用,便可以对其进行评估和需求分析,决定是否需要归档或者销毁。
(二)数据血缘与图数据库
目前数据血缘关系的技术实现主要用到了图数据库的技术,通过图数据库,直观地展现各节点之间的关联方式和关联关系,以及数据的流转和血缘关系。
图数据库(Graph database)并非指存储图片的数据库,而是以图这种数据结构存储和查询数据。图形数据库是一种在线数据库管理系统,具有处理图形数据模型的创建、读取、更新和删除(CRUD)操作。
与其他数据库不同,关系在图数据库中占首要地位。这意味着应用程序不必使用外键推断数据连接。
目前主流的图数据库技术表现优异且使用率高的是Neo4j。
Neo4j是一种高性能的、NoSQL图形数据库,它将结构化数据存储于网络而非表中。且是嵌入式、基于磁盘、具备完全的事务特性的Java持久化引擎,该引擎具有成熟数据库的所有特性。
通过该技术实现数据血缘的可视化方法包括以下步骤:
1、解析SQL语句,生成相应的抽象语法树,对于每个抽象语法树,深度遍历该抽象语法树的每个节点,在每个节点采集相应的节点数据;
2、将采集的节点数据关系存储于Neo4j图形数据库;
3、将异构数据源的信息引入血缘关系系统,形成血缘关系,便于图形化展现各数据源、表间的依赖关系和血缘关系。
该技术可以有效提升数据中心元数据管理能力的层次,加强管控平台内部数据流转,理清数据来龙去脉,打通各异构数据源隔阂。由此可见,血缘关系作为一座桥梁,连接各数据源。
四、案例分享
为详细说明如何基于数据血缘梳理的基本理念,通过图数据库等技术手段解决资管业务数据生态建设过程中的数据质量管控问题,本文以我司数据中心建设过程作为实际案例,进行相关分享和交流。
(一)数据质量困境
2015年起,公司启动“数据中心”项目。经过近5年的持续建设,数据中心已经发展成为拥有数千张数据源表,支撑各类监管报表、委托人报表、管理层报表以及诸多临时数据需求的服务平台。
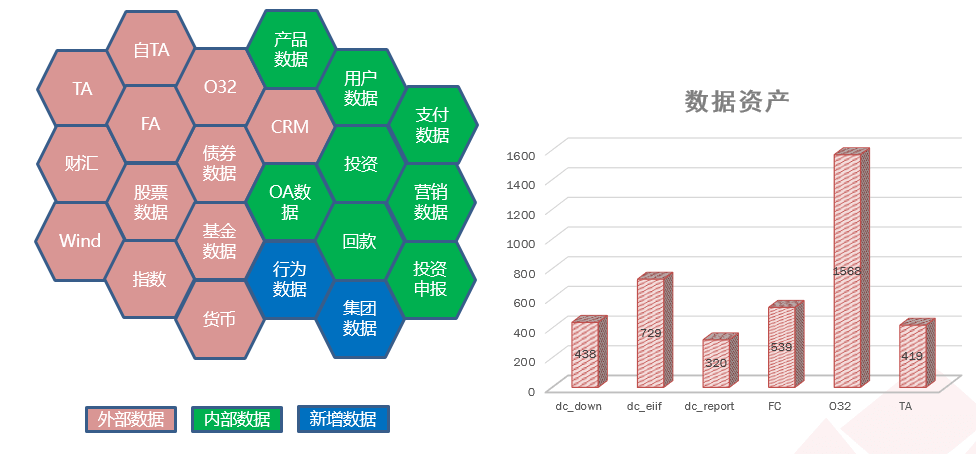
图1.1数据源分类和数据资产
然而,由于建设过程中存在历史客观原因,给数据质量的管控带来了较大的困难,进而影响到报表准确性以及数据服务效率的提升。例如:
1、数据源复杂性指数级增加
从数据源来看,数据中心主要有三大数据来源:内部数据,包括投资交易、估值、登记过户、CRM等核心业务系统中的数据;外部数据,包括财汇、Wind、指数、行情资讯等相关数据;其他数据:包括行为数据和集团数据等。
随着数据中心的不断建设运行,这些数据源不仅在数量上快速递增,而且因公司业务的发展演变、系统版本的更新迭代、外部数据供应商的相互差异等,其复杂性也与日俱增。
以估值系统从赢时胜V2.5升级到V4.5为例,业务逻辑发生大量更改,直接影响到后续ETL逻辑及各类报表开发。由于当时缺少清晰的数据血缘关系说明,为保证数据质量以及前后口径一致性,促使大量使用到估值数据的报表和前台数据应用重新梳理确认取数逻辑进行重构。
2、人员配备及团队发展迅速
如何有效利用数据源、建设数据仓库、梳理ETL逻辑、形成清晰的数据分层结构、最终实现数据的价值实现,需要长期积累熟悉数据表结构和专业业务领域知识,同时非常考验数据中心人员建设能力。
在人员配备和团队建设方面,公司数据中心建设从一开始的少数成员到后期团队不断发展壮大,并非一蹴而就。伴随团队规模的不断扩大,在缺少统一的数据标准和较为全面的公司数据资产视图的情况下,新加入的团队成员如何快速找到数据关联关系保证数据质量,除了依靠其本身的技能和相关经验外,更依赖于数据血缘关系的关联性处理。
以资管业务各类报表中常用到的“申购金额”为例,在既定逻辑下,需要同时提取“02”和“39”两种申购类型的金额进行汇总计算。而在缺少数据血缘关系的情况下,数据中心新成员如果缺少足够专业业务领域知识,则有可能只提取“02”类数据,而导致最终报表数据的准确性出现偏差。
3、临时性需求响应及非标准化操作
在数据中心的运行服务过程中,常常会出现数据需求方临时提出特定数据需求,并且由于任务时间紧迫,导致数据中心技术人员未按时完成报表开发,进而引发跨数据层访问、逆向数据分层跨层访问、表自身循环使用、部分逻辑重复计算等问题。
上述问题不仅会严重影响到数据质量的管控,还对相关系统实时显示数据的准确性产生一定程度的影响。
因此,无论是哪种客观原因给数据中心持续建设带来的挑战,都急需数据血缘梳理,以更好的追溯数据流向、保证数据质量。
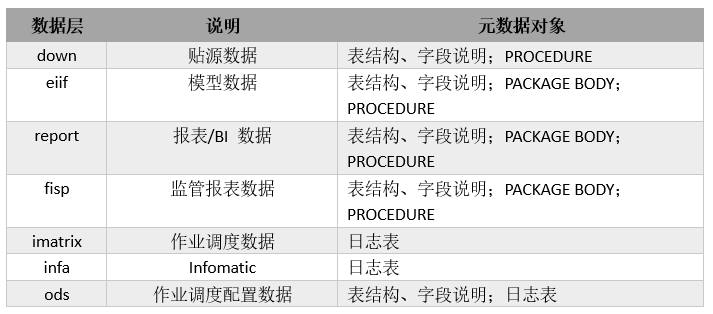
数据血缘属于数据治理中的一个概念,是保证数据融合(聚合)的一个手段,通过血缘分析实现数据融合处理的可追溯。数据血缘关系具有层次性,分为数据库级别、表级别和字段级别三种,数据库、表和字段,是数据的存储结构。而存储结构决定了血缘关系的层次结构。所以不同类型数据的血缘关系层次结构亦然不同。为解决数据中心现状和运维难点,以及任务调度管理,尤其是异常处理等问题,高效追踪数据来源和数据血缘关系,在以现有的数据仓库建设基础上,设计通过获取Oracle源数据解析PROCEDURE和PACKAGE BODY,实现表级别的数据血缘关系。
数据仓库建设目前是以Oracle作为数据存储、计算引擎,利用工具 Informatica做ETL处理,使用IMatrix作为调度系统。基于证券、基金、资产管理行业技术实现的特点,表的部分字段是通过Function从其它数据字典表获取,所以在PROCEDURE和PACKAGE BODY中存在许多Function函数,这些业务逻辑也需要技术能够实现。公司通过Oracle的元数据和使用Druid的SQL解析器来解析如下数据分层的PROCEDURE和PACKAGE BODY,以及部分表。
以此为基础,数据血缘的总体设计思路如下图:

图2.1 数据血缘总体设计图
数据血缘总体设计图接口设计分为三层:
1、 表级别的依赖,需对TASK,JOB,TABLES的层级,因类型的不同做不同表结构设计和业务实现设计;
2、信息钻取层,需要对TASK,JOB,TABLES等节点做向下钻迭代查询的可复用接口;
3、表层依赖,为单向表级别依赖链。
为实现上述三层接口设计,提供了如下的解决方式:
通过获取Oracle数据库的元数据信息,再利用Durid的SQL解析器,利用词法分析、语法分析,抽象语法树(AST:Abstract Syntax Tree)和Visitor解析元数据的SQL,基于Spring boot开发框架,实现具体的业务逻辑的代码开发,将解析的结果存储到MySQL的目标表中,实现了一套基于Oracle数据仓库的数据血缘分析工具,来完成各个数据表之间的数据血缘关系梳理。具体步骤如下:
1、 利用数据分层的Schema名,从Oracle元数据USER_SOURCE获取所有的PROCEDURE和PACKAGE BODY的过程名。
2、 利用任务调度配置表获取所有的存储过程和报表及指标的数据列表。
3、 分别处理与第二步有关的PROCEDURE和PACKAGE BODY,利用USER_SOURCE根据过程名分别获取存储过程对应USER_SOURCE.TEXT字段, 按照存储过程PROCEDURE名称,将代码下载存储到本地文件中,去空格,统一大写处理,通过获得开始、结束行数,获取真正的存储过程代码。
4、 解析PROCEDURE的存储文件,预处理,去掉注释和BEGIN,END,COMMIT等相关代码。再使用 Druid的 SQL解析器解析,获取字段,关联条件和筛选条件。
5、 将所解析的结果数据信息插入到目标数据库表中。
6、 再将目标数据库表的数据插入到Neo4j图数据库的表中,通过Neo4j自动创建图的关系。
上述第5步解析结果的目标表表结构设计如下表:
血缘关系表 tb_pro_link

样例数据:
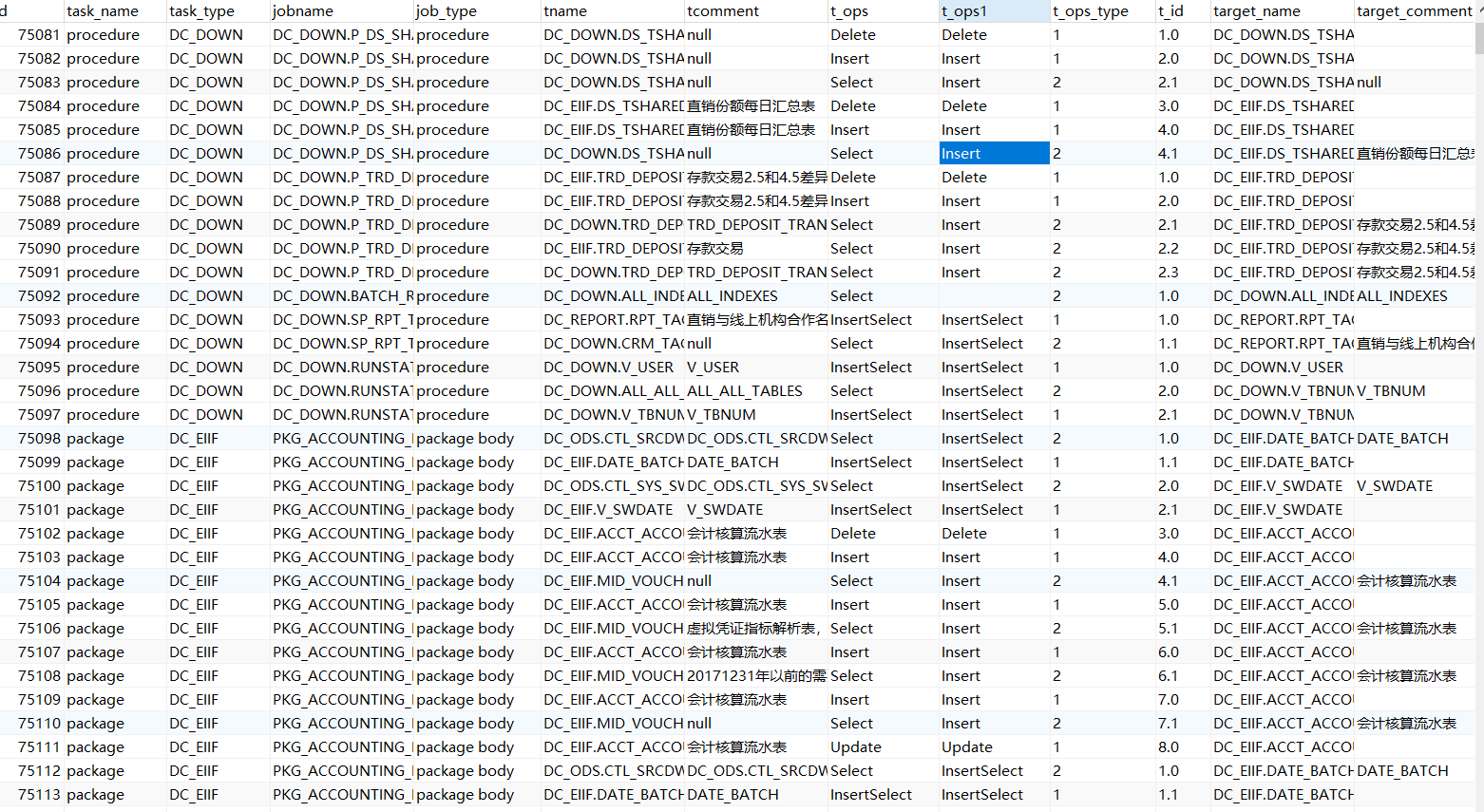
图3.1 数据血缘关系表样例数据图
数据若只存储在数据库中而无法展示其血缘关系,数据依然是无用的。在第五步的生成目标数据的基础上,将这些数据导入到图数据库Neo4j,实现第六步数据血缘关系的可视化。只有通过可视化,血缘关系方能清晰可见。
根据数据血缘关系的特点,公司设计了数据的血缘关系可视化图形。流程如下:
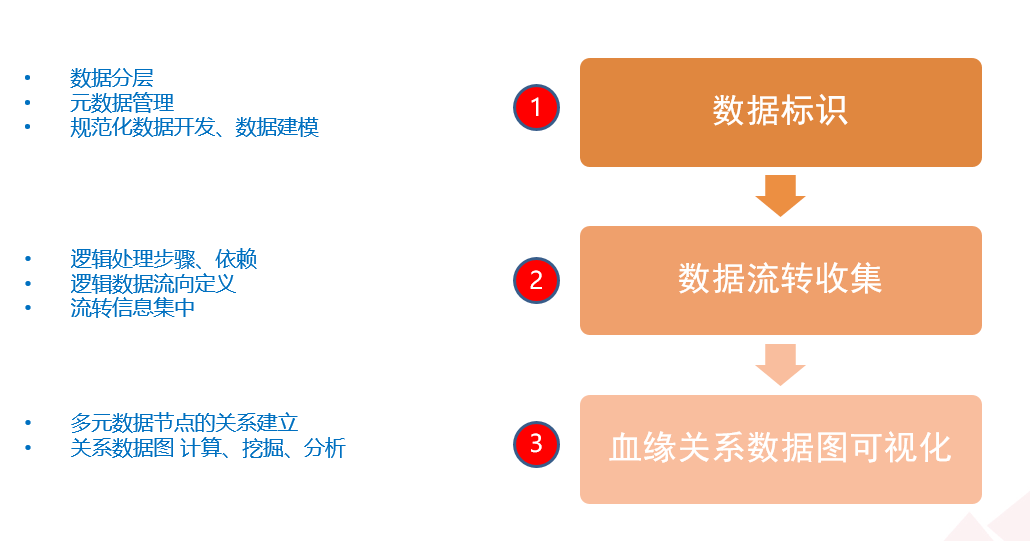
图4.1 血缘关系可视化图形
(二)实现过程
- 获取MySQL目标表tb_pro_link的相关字段。
- 解析获取表tb_pro_link数据内容,对相关表名和目标表名一致,且是依赖关系的数据不予以落到Neo4j数据库。
- 将其余的数据建立关系存储到Neo4j数据库中。
- 利用图数据库Neo4j的特点,通过相关查询语句获取表级别的依赖关系。
利用生成的Neo4j图数据库,举例展示相关结果:
指向表DC_EIIF.ISSU_ISSUE_MAPP的关系及节点
MATCH p=(n:Table)-[P_ISSU_ISSUE_MAPP]->(m:Table) where m.fullname= 'DC_EIIF.ISSU_ISSUE_MAPP' return p

图5.1 相关表DC_EIIF.ISSU_ISSUE_MAPP关系节点
根据此图找到源表,带箭头的为目标表,中间连线是指存储过程的使用和生成关系,可发现: DC_EIIF.MID_VOUCHER_ACCTITEM_SPLIT_45 与DC_EIIF.ISSU_ISSUE_MAPP 有循环使用现象。打开投资品种表DC_EIIF.ISSU_MKT_ISSUE,展开其与之所有相关联的节点和关系,如下图:
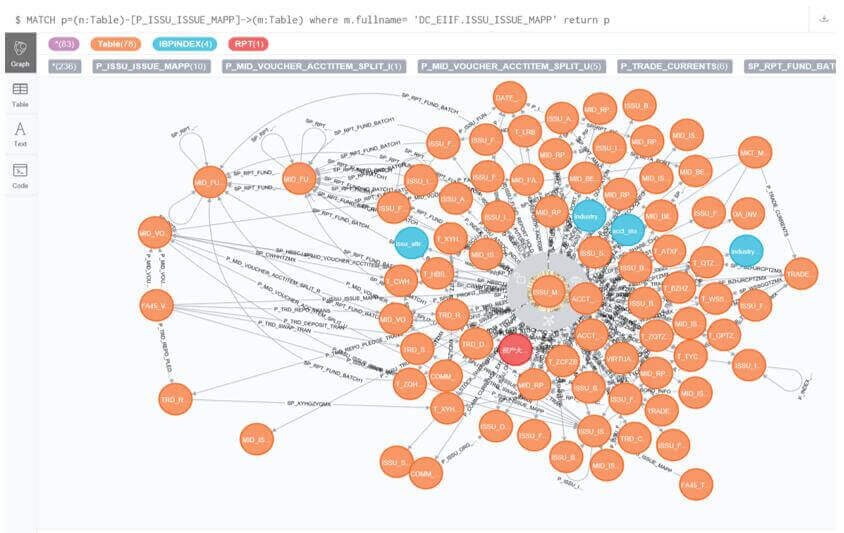
图6.1 DC_EIIF.ISSU_MKT_ISSUE关联节点展开图
从上述图看,可见以上业务的复杂性及其使用的广泛性,同时部分节点存在使用问题,需要针对性的数据表溯源。
查询存储过程中,直接使用了原始数据层财汇(finchina)表
MATCH p=(n:Table)-->(m:Table)
where n.fullname=~ '.*FINCHINA.*' return p
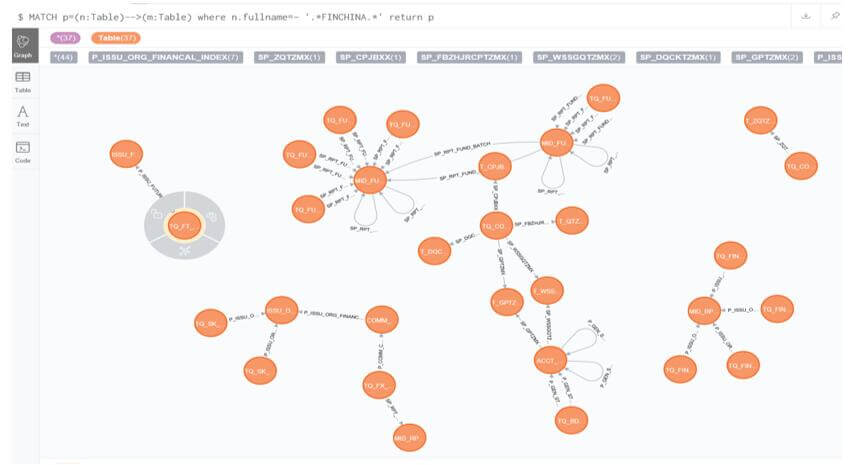
图7.1 直连Finchina相关表关联节点展开图
从上述图看,有部分存储过程直接使用源层数据,跨原始数据层访问,而没有真正将使用数据中心的数据,或者将源数据同步到数据中心。
查询主题之间关系举例:
查询 n与m之间的任何关系,where条件为n,m的匹配条件 FUND主题与ISS主题的关联关系(涉及到的存储过程),具有16个节点,23条关系。
MATCH p=(n:Table)-[*]->(m:Table)
where n.fullname=~ '.*FUND.*' and m.fullname=~'.*ISS.*' return p limit 25

图8.1 FUND主题与ISS主题关系表
关系方向的查询,并限制展现关系条数数量
n与m之间的任何关系 where条件为n,m的匹配条件 关系深度为1到3,关系条数限制25条
ACC主题与ISS主题的关联关系(涉及到的存储过程)
MATCH p=(n:Table)-[*1..3]->(m:Table) where m.fullname=~ '.*ACC.*' and n.fullname=~'.*ISS.*' return p limit 25
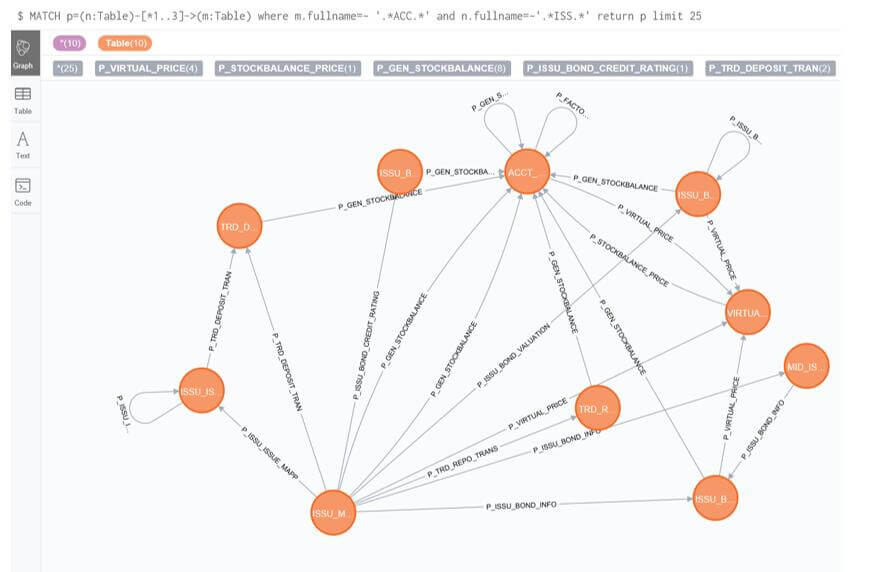
图9.1 ACC主题与ISS主题三层关系表
(三)数据血缘实质意义
通过上述血缘关系的生成,对于数据治理保证数据质量,重新调整数据分层、数据迁移,避免数据分层跨层访问,对更改数据表影响分析与溯源,ETL逻辑调整等具有十分重要的指导意义,具体体现在:
1、解决直接访问源数据层数据问题。通过不同数据源的查询,分析出ETL或者报表,临时需求数据等直接使用dblink访问源数据,利用数据采集解决此问题。
2、解决数据跨层、逆向跨层,表自身循环使用问题。通过血缘关系找到数据跨层问题表,分析其影响度做相关逻辑调整,避免正向或逆向跨层访问的问题,找到自身循环使用的表,并重新做逻辑调整。
3、解决模型修改或者原始数据变更数据影响问题。若原始数据因数据异常造成数据质量问题,或因ETL模型逻辑调整,不同版本数据切换,或数据源切换,导致后续数据使用问题,如各模型层、报表、临时需求等进行根本原因分析,最大程度降低风险。
4、解决数据使用方发现数据问题。通过目标表的血缘模型进行溯源,快速定位问题、分析数据链路、评估数据质量,为排查问题提供理论依据和实战指导。
5、分析任务复杂度或各个节点表的血缘关系及影响度,梳理重要表和节点,评估其数据价值及数据受众。
6、数据归档,针对不存在血缘关系的表进行归档。
7、为数据仓库从Oracle迁移到大数据平台提供理论依据,分析各层次的依赖关系和影响。
8、帮助新入职员工了解数据特点,公司领导可清晰理解业务逻辑的复杂度和表调整的相关影响进行高效沟通。
五、小结
数据生态建设基于数据血缘的跟踪、设计、执行、评估实现数据流通、数据服务、数据洞察,通过企业在制度、组织、战略管理进行业务数据治理及分析数据治理,从统一的数据架构平台管控治理,真正实现智能运营、合规管控、风险管理、价值创造。
数据生态建设给企业带来巨大商机的同时不断冲击传统数据生态管理模式。正因传统数据生态管理模式无法承载多元需求,促使企业持续加大投入,不断优化技术架构以实现半结构化、结构化数据高效处理。正因如此,企业对于数据汇聚、数据共享、数据应用、数据治理和数据安全提出更高要求,更是将数据治理作为自身发展的核心战略性目标管理。通过数据血缘,助力企业加快数据汇聚、实现数据共享、深化数据应用、完善数据治理、强化数据安全、加强组织保障,不断增强客户的体验感及潜在预见性安全问题,真正实现数据确权、数据质量、数据安全、隐私保护、流通管控、共享开放的新时代管理模式,推动企业全局性数字化转型,打造成熟完整的数据生态系统,将网络化数据社会与现实社会有机融合,进行一站式开发,全方位管理,提升资管业绩。
参考文献
[1] 孟庆江.数据治理-金融科技助力券商转型的灵魂. [J] 中国社会科学院金融研究所.2017,04
[2] 王晓玲;谢鸿强;刘安;董逸生.数据仓库建模工具的研制[J]. 东南大学2020
[3] 张帜.Neo4j 权威指南.[M] 清华大学出版社 2017
[4] 金泳.基于数据仓库的数据血缘管理研究. [J] 2019
[5] 姜振华;张晓磊.基于血缘关系的数据分析方法的建立[J].科技情报开发与经济.2015,04
[6] 姜振华,张晓磊. 基于血缘关系的数据分析方法的建立. [J]《图书情报导刊》.2015
[7] 李旭风,罗强.面向数据字段的血缘关系分析. [J] 中国金融电脑.2016
[8] 梅宏.建大数据治理体系 造良好产业发展环境.[R] 中国信息化周报.2018
[9] 蒋东兴,高若楠,王浩宇. 证券期货行业监管大数据治理方案研究.[C] 2019
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号