本文共字,预计阅读时间。
文/国联证券股份有限公司互联网金融部任志翔、孙晓、范孝辰
(本文为“证券机构数字化转型与证券科技创新”征文活动入围文章。)
1、研究背景介绍
随着近几年证券行业的快速发展,各家券商的客户量都出现了较大增长,同时自2015年以来,互联网证券业务以及券商整体佣金率的下滑,已经让券商通过新增客户来增加营收越来越难[1]。因此针对公司已有的客户进行存量挖掘,从投入以及获得回报之间比例的角度判断,相对于开发外部渠道新增客户,是更加适合券商的选择。
为提高客户运营的效率,目前很多证券公司都会采用将客户分级的策略,主要是按客户资产量分级,类似于普通客户、财富客户、高端客户等[2],而从客户所占比例的角度来看,占比最大的是资产量相对较低的普通客户。这部分客户占比往往超过了90%,但由于分支机构的人力有限,往往公司的理财顾问会将精力更多地集中于资产量较高的中高端客户,而忽略了针对于普通客户的主动服务。因此近年来,券商数字化转型的必要性越来越凸显[3],结合大数据以及信息系统,将许多服务内容转变为线上模式、自动化模式,针对于体量较大的普通客户,也能够提供许多个性化的主动推送服务,例如新股申购提醒、基金理财申购提醒以及个性化的产品推荐等等。
2、我司场景化运营模式简介
我司互联网金融部根据目前占公司客户总量绝大多数的普通客户的服务需求,已经形成了初步的自动化智能运营模式,在此基础上,又发展提出了场景化运营模式,充分发挥数字化、自动化运营相对于传统线下营业部理财顾问服务运营模式的优势,即覆盖范围大,投入人力成本少。本文涉及了场景化运营模式中的两种场景,活跃度下降客户场景和非销户隐性流失客户场景。
首先明确两种场景的客户定义,活跃度下降客户的定义为过去六个月内有过交易行为,但最近三个月没有交易行为的客户;非销户隐性流失客户的定义为客户账户状态正常,且历史上曾经有过交易行为,但过去六个月无交易行为且期间峰值资产小于300元。之所以选定这两类客户以及相应确定三个月以及六个月两个关键时点,是因为客户交易活跃度受市场行情影响,在三个月内出现较大波动的可能性较大,因此针对活跃度下降的客户,并不一定有流失倾向,通过一定的服务手段,例如个性化推送基金产品仍然可以达到使其重新恢复交易的效果[4];但如果时间周期扩大为六个月,客户仍然未进行交易且资产已经下降至300元以下,那么即使客户未销户,仍然可以基本判断该客户已经出现事实上的流失,此时再去采取挽回措施,成功的可能性将会大大降低。
3、流失预测模型开发过程介绍
3.1 传统流失预测方法的缺陷
传统的客户生命周期理论其实也是一种流失预测的手段[5],但局限性很明显,将客户划分为成长期、成熟期、衰退期等划分过于简单,且当客户进入衰退期时,很大概率客户已经事实上流失,不能很好地达到“预测”的效果。利用大数据进行的流失预测模型则在采用客户数据的角度有较大局限性,通常仅采用当前时点的客户数据,无法将客户一段时间内的特征变化纳入模型范围。例如从当前时点出发,取客户一段时间的资产均值、交易均值等,再将大量客户的数据汇总,进行聚类分析或逻辑回归,根据一段时间后客户的流失情况,进行训练测试,得出用于预测客户是否会流失的模型[6]。这种方法局限性在于,采用的数据是静态的,即单个客户纳入模型时,事实上只纳入了该客户这个时点的特征,没有纳入其变化的趋势;另外这样建模事实上是在通过分析不同客户之间的区别来找出一个判断所有客户是否会流失的规律,但不同的客户流失发生之前的特征本身就是不同的,举例:客户A当前资产为10万,但过去一年间A客户的日均资产为100万,客户B当前资产为5万,但过去一年间B客户日均资产只有2万;则如果单从资产特征来分析,A的流失概率显然小于B;但事实上可以看出,B的资产事实上出现了增加而A出现了资产流失,合理推测A的流失概率反而更大。因此本文将要探讨的流失预测模型采用的是客户一段时间内多个时点的数据,来达到将客户的变化趋势作为预测主要判断依据的效果。
3.2 大数据流失预测模型与场景化运营模式之间的关联
大数据流失预测模型预期预测效果为,在客户流失前一段时间对于将要流失的客户给出预警,并通过线上线下推送手段相结合的方式,提前对于该部分客户进行挽留。从营销投入回报比例的角度考虑,在客户将要流失前进行营销投入进行挽回效果是好于在客户流失之后再进行挽回的。
非销户隐性流失客户此处定义为历史有过交易行为,但过去六个月无交易行为且期间峰值资产小于300元;从定义出发可以推论得出,当前仍有交易行为的活跃客户,三个月后不可能成为流失客户;而活跃度下降客户定义为:过去六个月内有过交易行为,但最近三个月没有交易行为;因此当前被定义为活跃度下降客户范围内的客户,在三个月后才有可能转化为流失客户。因此结合这两种场景,大数据流失预测模型预期预测的结果可以进一步明确为:针对当前的活跃度下降客户,结合其历史交易数据,预测该部分客户是否会在三个月后转化为流失客户。
3.3 流失预测模型开发详情以及改进过程
3.3.1 第一版流失预测模型
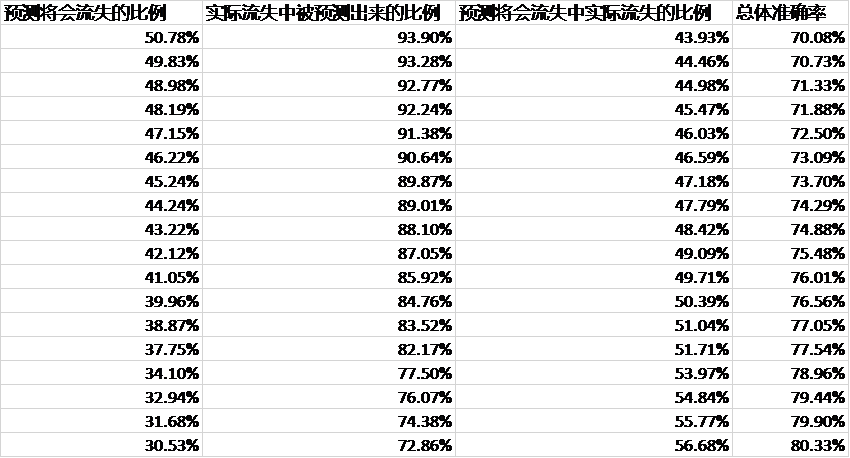
基于预期预测结果,第一版流失预测模型针对2019年10月的活跃度下降客户进行开发,使用该部分客户2018年7月至2019年7月之间的交易量数据,共涉及客户62847人,1701330条交易记录。客户交易量数据纳入模型的方法为,将2018年7月至2019年7月之间的时段按照20个交易日为一段划分为12个区间,将每个客户的交易量计算出12个数值(即12个区间内每个时间段内该客户的交易总量),作为12个特征值。同时再判断这部分客户到三个月后,即2019年10月份,是否已经转变为非销户隐性流失客户,转变为流失客户的即纳入正样本范围,未转变为流失客户的即纳入负样本范围,进行随机森林建模训练测试。针对这62847客户,模型给出的预测结果与实际流失情况的对比情况如下(随机森林模型可以通过选取不同的阈值给出不同的预测结果,因此最左侧为阈值从小到大变化对应的预测结果的变化)。

从这些数据中可以看出,针对于该部分客户的交易历史数据以及实际流失情况训练测试得出的模型准确度非常高,在仅给出占客户总数20%-25%范围内的预测结果时,就已经可以预测出90%左右的流失客户,总体预测准确度也达到了95%以上。
另外选取2020年1月份的活跃度下降客户数据,共涉及客户69122人,1927408条交易记录,交易记录时间区间为2018年10月份至2019年10月份,处理方法与之前相同,将其中240个交易日分割为12段。对这部分客户使用之前训练的模型进行预测,给出的预测结果与实际流失结果对比情况如下。

从对比结果可以看出,在预测流失比例相同的情况下,利用2019年10月份活跃度下降客户数据训练测试得到的模型,在预测2020 年1月份活跃度下降客户是否会转变为流失客户时,准确度出现了明显的下降。
从模型采用的客户特征角度分析,可以做出初步推论,市场行情因素会很大程度上影响客户的交易活跃度以及流失与否,第一版流失预测模型在开发时仅考虑客户交易量在不同时间段的变化,以此为依据来判断客户是否有流失的趋势并给出预测。因此在针对同一时点的活跃度下降客户进行预测时,给出的预测效果较好,而当针对另一时点的活跃度下降客户进行预测时,由于时点的变化导致的市场行情变化,会使得预测准确度出现变化。基于此推论,着手进行第二版流失预测模型的开发。
3.3.2 第二版流失预测模型
第二版流失预测模型从两个方面将市场行情影响纳入模型预测时考虑的客户特征范围内:
首先是采用不同时点的活跃度下降客户交易数据。由于归纳客户特征时,每个时点的活跃度下降客户均会取其历史上240个交易日的交易数据进行交易量的分段计算,因此可以将不同时点的活跃度下降客户样本视作同等权重的样本数据(即使该客户在不同时点多次出现,也可将其视为不同的多个样本,因为不同时点的客户的流失倾向也会随着市场行情变化而发生变化);以不同时点不同客户为单位进行数据收集,相对于仅针对单一时点不同客户为单位进行数据收集,一者可将市场行情因素纳入模型采用的特征范围内,再者同时也解决了模型可采用的样本量小的难点,进一步提高模型准确度。
其次是将市场行情因素进行特征归纳并纳入模型。由于采用了不同时点的客户数据,因此市场行情变化本身也可直接作为特征纳入模型。此处采用以下方式归纳出四个特征纳入模型,以2019年10月的活跃度下降客户举例:

客户的交易活跃度下降出现在2019年4月至2019年10月,即客户在2019年4月至7月的区间内进行了交易,而在2019内7月至10月的区间内没有进行交易;取2019年4月至2019年10月的上证综指日涨跌幅数据。
以2019年7月1日为分界线,归纳出四个特征值,2019年7月至10月之间指数平均涨跌幅为-0.0698%,日涨跌幅大于0的比例为50%,2019年4月至7月之间指数平均涨跌幅为-0.0520%,日涨跌幅大于0的比例为48.33%。
用这种方式将不同时点的指数行情四个特征作为客户的特征纳入模型当中,更加直接地将行情变化因素纳入了模型考量范围之内。
从以上两方面对第一版进行改进得到的第二版,总共包含客户512080人次,交易数据记录30000000条以上。训练测试得到的模型与实际流失结果比较情况如下:
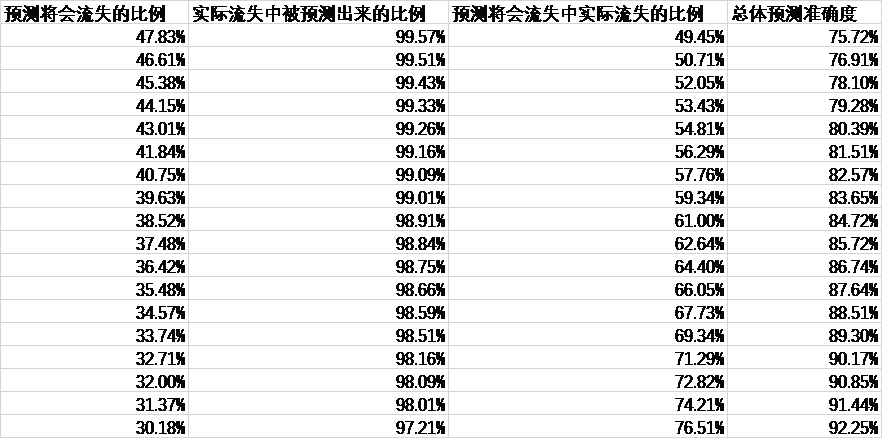
与第一版训练测试的结果相比较,第二版并无明显准确率方面的提升,但与第一版模型针对另一个时点的客户进行的预测结果相比,准确率明显较高。第二版模型共采用了十个时点的活跃度下降客户数据,为2019年4月、5月、6月、7月、8月、9月、10月、11月、12月以及2020年1月,使用第二版模型针对2020年2月的活跃度下降客户进行预测,结果如下:
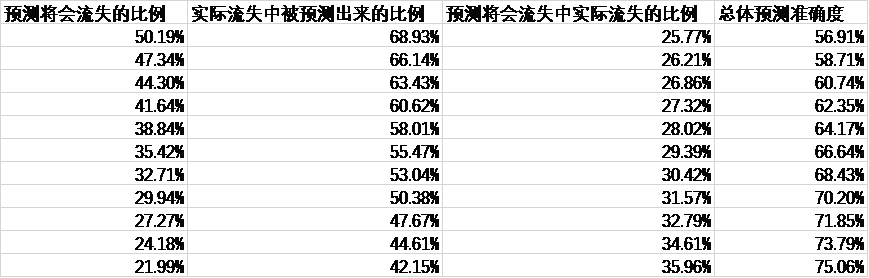
从数据当中可以看出,模型的准确度仍然出现了下滑;下滑的原因可能是由于随机森林算法本身的局限性,即由于只采用了十个时点的客户数据,在市场行情变化方面的特征实际上提供给模型的只有十组固定的特征值,而实际上市场行情因素应当为一个连续的影响因素而不是离散型的固定值,这导致了模型出现了过拟合;当一组全新的客户数据包含了模型训练过程当中不曾遇到过的市场行情特征值,容易出现准确度的下滑。
第二版流失预测模型的另一个缺陷是,虽然样本数据量相比于第一版模型大大增加在一些情况下提高了模型的准确度,但同时也带来了训练耗时的极大增加。第二版模型训练约耗时120小时左右,而与此相比第一版模型仅耗时约1小时左右。模型训练耗时过长不利于模型的更新迭代,同时也极大消耗了信息技术资源。
3.3.3 第三版流失预测模型
基于第二版模型开发过程中发现的两处主要缺陷,第三版模型采用了对应的解决方法:
将市场行情因素的纳入方法进行修改,不再直接将市场行情因素归纳出的四种特征值与客户交易量特征一起提供给模型,而是将之前十个时点的行情特征与十个时点的活跃度下降客户之后三个月内转化为流失客户的比例单独进行线性建模,转而预测不同时点时活跃度下降客户三个月后转化为流失客户的比例。数据如下:
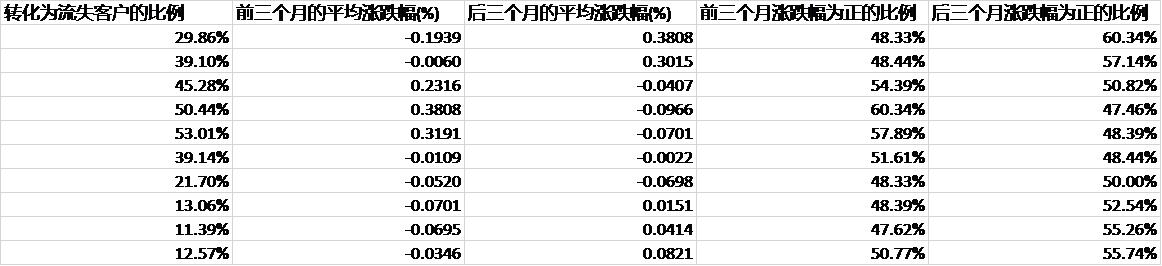
以转化为流失客户的比例作为因变量进行线性回归,得到的结果如图:
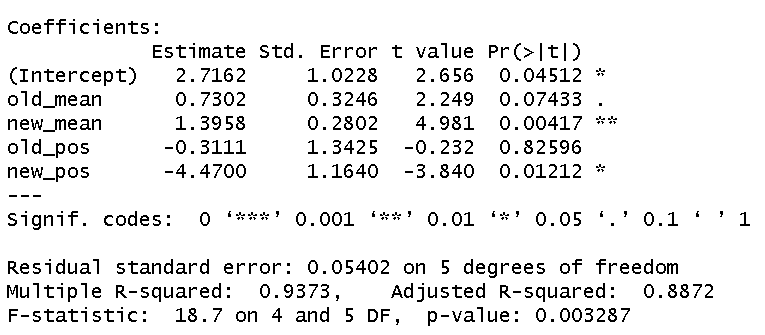
从t值可以看出,前三个月平均涨跌幅、后三个月平均涨跌幅以及后三个月涨跌幅为正的比例与流失比例有显著的线性关系,而前三个月涨跌幅为正的比例则不显著。因此剔除前三个月涨跌幅为正的比例这一变量之后,再进行线性回归,得到结果如下:
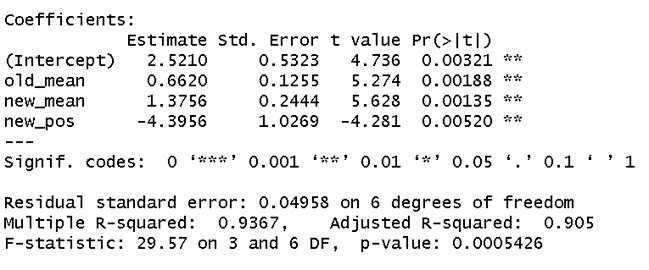
线性回归拟合度为0.9367,说明流失比例与市场行情归纳得出的三个特征之间有非常显著的线性关系,可以通过当前的市场行情对之后三个月内客户流失的比例进行有效准确的预测。因此第三版流失预测模型开发时将市场行情特征单独抽取建立线性预测模型,不再纳入随机森林模型采纳变量范围之内。
针对512080人次的客户数据,由于直接整体进行随机森林建模耗时过长,将总体的客户数据分割为25段,同样以随机森林模型建立25个分支模型,预测时使用所有的分支模型同时进行预测,最后将25个模型预测给出的预测值取平均值作为最后预测的结果。训练测试的结果如下:
线性回归拟合度为0.9367,说明流失比例与市场行情归纳得出的三个特征之间有非常显著的线性关系,可以通过当前的市场行情对之后三个月内客户流失的比例进行有效准确的预测。因此第三版流失预测模型开发时将市场行情特征单独抽取建立线性预测模型,不再纳入随机森林模型采纳变量范围之内。
针对512080人次的客户数据,由于直接整体进行随机森林建模耗时过长,将总体的客户数据分割为25段,同样以随机森林模型建立25个分支模型,预测时使用所有的分支模型同时进行预测,最后将25个模型预测给出的预测值取平均值作为最后预测的结果。训练测试的结果如下:

与训练测试的准确度相比有一定下降,但与第二版的结果相比,预测新数据时准确度的下降已经明显减少。
进行两方面的改进之后,第三版流失预测模型已经具备了实用性。在使用客户数据进行流失预测之后,在选定实际推送预警时,可以以利用当前市场行情进行线性预测的自然流失比例为参考,选定合适的预测将会流失的比例并进行推送。
4、流失预警实际应用与推送效果展示
流失预警推送主要是针对证券公司分支机构的理财顾问,推送时向前台业务人员展示几方面的要点:客户的历史峰值资产、客户的当前资产以及客户流失的概率。
展示效果如图中所示(涉及客户隐私,此处隐去客户姓名、手机号码以及客户编号等敏感信息)
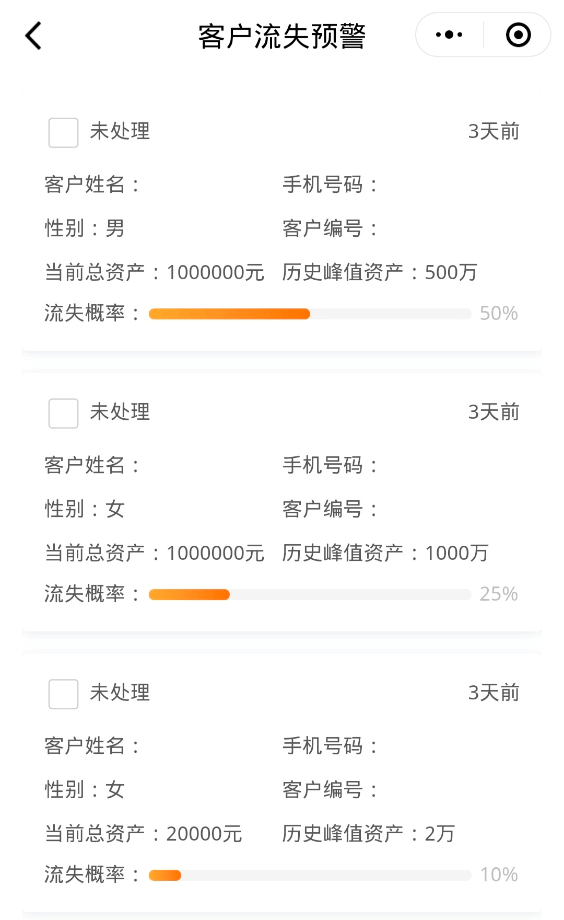
由于理财顾问以一对一服务为主要形式,无法保证所有发出预警的客户均能服务到;因此在向理财顾问展示时需要提供足够的信息给理财顾问,例如该客户历史峰值资产较高且流失概率较高,当前总资产已经有下降的趋势,这类客户理财顾问应当优先进行服务挽回;若客户流失概率较低,则在服务能力有限的情况下,理财顾问可以选择不进行一对一的服务挽回,转而使用线上营销推送,发挥数字化运营的优势:覆盖面广且不消耗人力资源。
5、分析结论与实际应用评价
基于场景化运营模式的大数据流失预测模型相比于传统的客户流失预测方式,首先基于场景划分,缩小了总体需要预测的目标客户范围,使得模型本身需要预测客户未来趋势的难度有所降低;其次在模型开发过程当中,相比于传统的利用客户静态特征进行预测,将客户的历史交易数据处理成趋势特征,同时采用不同时点多次采样的方式,扩大了样本数据量,提升了模型准确度以及实用价值;另外纳入了市场行情因素,在券商客户运营领域这一因素显得尤为重要。结合以上三点创新之处,使得最终的预测模型能够直接给予前台业务人员精准、简洁易懂的指导建议作用,同时也为我司客户运营的数字化转型提供了有力的支持作用。
参考文献
[1] 李博雅. T证券公司客户开发的渠道策略研究[D]. 2013.
[2] 朱海东. 证券公司客户价值分析系统的设计与实现[D]. 大连理工大学, 2014.
[3] 孟庆江. 从应用视角看大数据对证券公司的影响[C]// 创新与发展:中国证券业2015年论文集. 2015.
[4] 陈晓霞. 银河证券营业部客户分类与活跃度预测[D]. 2007.
[5] 邓祥永. 客户关系生命周期与券商客户价值的实现[J]. 经济师, 2002, 000(005):126-128.
[6] 刘硕. 基于数据挖掘的证券公司客户流失分析研究[D].
文中数据来源说明:文中所引用数据均为我司内部数据库以及机器学习平台给出,非外部公开数据源
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号