本文共字,预计阅读时间。
为了传播金融创新典范,推进金融供给侧结构性改革,推动金融业服务实体经济,以及促进实现经济高质量、发展的目的,由北京市地方金融监督管理局指导,清华大学五道口金融学院、清华大学金融科技研究院主办,未央网承办推出“首都金融创新与发展”公开课,邀请金融行业嘉宾分享金融项目的创新模式,以及对行业未来发展前景的深度思考。
在首都金融创新与发展公开课的第四模块“金融科技创新与赋能”中,我们非常荣幸邀请到了慧安金科CEO黄铃做客直播间,带来《人工智能在金融反欺诈和反洗钱中的应用》主题分享。以下整理来自嘉宾分享实录:
人工智能技术介绍
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的、能以与人类智能相似的方式做出反应的智能机器,其产业生态格局可以划分为基础层、技术层和应用层。基础层是未来支撑人工智能的层次,支撑技术工人所需的硬件设备、计算平台和各种相关的体系架构等;中间的技术层包括计算机视觉、自然语言处理等基于不同算法建立的模型;在此基础上形成各种应用,比如机器人、无人驾驶、智能金融等等。
人工智能的发展经历了多次浪潮。从上世纪50年代的计算智能时代,到60年代,先驱们开始提炼出各种规则和专家系统,并且,随着传感器对外界的感知和数据的提取越来越多,计算机逐渐具备一定的对外界信息进行加工、并调整系统的能力,由此进入感知智能时代。随后,由于定义好的规则无法处理某些外界感知信息,专家开始发展基于统计模型的机器学习方法,以及基于神经网络的推理和建模方案。但是因为收集的训练数据有限和算力不足,神经网络没有得到大规模发展,相反,传统的基于统计的机器学习模型被广泛应用。而2010年以后,随着云计算、大数据计算和并行处理的算力不断发展,以及大量标签数据的存在,深度学习逐步走向前台,人类能够训练出更大、更复杂的基于神经网络的模型,其图像识别的准确率提高了将近20个百分点,逐步超越人的能力。
人工智能中一个核心的领域是机器学习,其主要功能是从日常数据中学习内在模式,从而让机器不断进化、拥有智慧,它是很多其他领域的理论基础,包括自然语言处理、图像识别、知识图谱等领域。
具体地,学习的数据指样本、样本特征和样本标签,比如在风控监管合规领域,金融账户属于样本,账户客户的交易额度、交易频率等属于特征,正常客户/欺诈客户/洗钱客户属于标签,对于洗钱客户,他的账户可能经常进出几十万、几百万,快进快出,而且很少不留余额,这是洗钱客户的一些属性。面对这些数据,有多种机器学习算法,包括有监督学习,无监督学习的聚类、异常检测、维度缩减算法,以及介于两者之间的半监督学习,总体上机器学习的过程分为训练和预测两个部分。
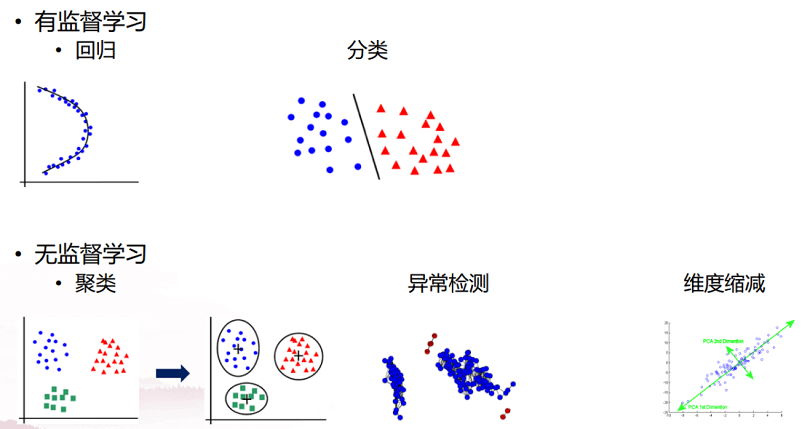
有监督的机器学习中,以合规领域反洗钱的应用为例:在训练阶段,让机器学习来学习历史上反洗钱专家已经打出标签的历史样本,这些样本包括客户的年龄、性别、交易行为、交易额度等信息。首先把这些客户信息转换成数值表达方式,特别是在一个高维的特征空间里表达为向量,高维空间中有很多特征维度来描述账户行为。然后通过机器学习去学习一个分类器,即特征空间中的一条直线,它能够很好地把两类点分成两部分。分类器的种类很多,比如支持向量机SVM是一个maximum margin 分类器,它能够计算一个决策边界,让好/坏样本到决策边界的最小距离最大化,这样即使在对样本数据采集不准确时,样本点也不容易被错误地划分到另外一方。在预测阶段,可以直接用这个模型对新客户的数据信息进行分析预测,判断他是洗钱还是正常。
在无监督机器学习中,无监督是指没有任何标签信息来告诉算法哪个对象/数据点属于哪个分组。其中,聚类算法是根据点之间的关联关系,依照它们彼此距离进行聚类。比如,将账户余额很小、交易频率也很小的用户归类到一个团体;将账户余额很小、交易频率很高的客户聚类,这可能就是洗钱客户。聚类算法大体上分为分区式聚类算法(构建多个分区,使用一些标准进行评估)和层次式聚类算法(使用一些标准进行对象集层次分解,先找到距离最近的两点,再在这两点基础上找到与其距离最近的,以此类推)。
异常检测算法是找到与数据集中的其他点明显不同的异常点。比如在一个区间里,有N1和N2两个区域,其中有大部分点聚集,就认为它是正常区域。但是有一些点离主要区域的点的距离都很远,就可以用异常检测的方法把这些异常点与N1、N2中的点区分开。
人工智能在金融反欺诈和反洗钱中的应用
人工智能在金融机构的应用范围非常广泛,最多的是在风控、合规、监管、内控等领域,具体包括交易反欺诈、反洗钱、内控审计和营销反欺诈,在这些场景中,会应用上文提及的机器学习算法分析客户基本信息,以识别可疑交易、欺诈账户,甚至风险洗钱的团伙等。此外还有智能运营领域,包括风险定价、信用评估、产品推荐,甚至在公开市场上的投资研究、信号提取和投资组合推荐。下面主要集中于风控、合规、监管相关的领域。
人工智能在这些领域的主要目标根据业务或有不同。在交易反欺诈方面,特别是信用卡盗刷、APP转账等欺诈,目标是在不过分打搅客户的情况下,大大提高欺诈案件识别的覆盖率。在反洗钱方面,目标是用机器学习建模识别出不是洗钱的方法,把它排除,并对洗钱账户进行分门别类的评分和分类,这样可以根据调查和审核人员不同的能力来分配不同的案件,帮助他们提高效率。在其他的领域目标也不相同,比如有些时候是要提高覆盖率,有些时候要优化业务流程,有些时候要优化已有的经验规则库,或者是用机器学习做出更好的、可解释的规则和模型,去帮助专家更好的调查、取证、审核。以下是一些具体场景和案例。
(一)人工智能实时检测伪卡盗刷交易
伪卡盗刷行为是指银行卡或信用卡被不法分子盗取了卡的磁条信息或芯片信息,然后伪造出新卡,再用这种新卡去ATM机取现,或者去店家的pos机上刷卡,购买商品然后转卖从而进行获利。这种信息盗取可能发生在很多场景中,比如在加油站被别人装了侧录器,或者是有些商家的数据库中存储了卡的信息,但商家数据库的安保等级较低,被黑客攻击,数据库被泄露。整个伪卡盗刷链条分成了3~4个不同团伙,包括卡片信息盗取、伪卡制作、用伪卡购买商品、转卖获利。这里目标是根据链条上的获利模式,用机器学习去设计开发模型系统,帮助判断交易是个人刷卡还是盗刷。
根据上文分析,伪卡盗刷的链条非常长而复杂,它需要盗刷几千张上万张的卡,尽可能在短时间内把卡里的钱都刷光,而且会买贵重、易携带、易变现的商品,比如黄金首饰、手机等,连续大额地购买,才能够盈利。这些原因导致盗刷必须有特定的模式。根据这些特点设计机器学习模型,从而能够区分盗刷交易和正常交易。但是这里无法排除正常人也会做连续大额交易、购买黄金、手机等贵重商品的情况,因此还需要根据具体业务和行业历史案例去理解海量数据中呈现的正常交易和盗刷交易的特点,从而能从多种维度精准地区分。具体地,需要做多种特征或衍生变量的计算,比如用户单位时间内刷卡的频率、刷卡的额度和密度跟它的历史总量相比的偏差、交易金额的分布分位数、通常的交易时间和地点、在大额交易前是否会事先查询和小额测试等等。然后用上述模型把特征进行组合,进行参数调优,根据历史样本训练出最佳的特征维度的组合,从而形成最优模型。
实践证明这种复杂模型的准确率很高,在排名Top300的可疑交易中能命中255笔,准确率超过80%,提高已有规则系统60%+的准确度;并且模型能够对99.95%的交易事件在20ms内响应,及时发现和阻挡可疑交易。这能够帮助银行和电商平台,进行非常准确的可疑交易的检测和拦截。
(二)银行全渠道洗钱交易识别
在银行的可疑交易监测体系中,银行有自己的内部规则系统,能够对银行每天发生的数亿笔交易进行批处理的检测,一年可能会检测出上百万案宗。但是银行的规则系统设计严格,经常会产生大量的误伤,高达95%以上的案宗都属于正常交易,需要一个有几百甚至上千人的人工审核团队对案宗进行人工审核,把其中几万宗真正的高危洗钱案识别出来。这些人工审核的成本很高,并且随着银行业务的快速发展,可疑案宗数量不断增长,远远超过人工所能支持的程度。
这种场景下,机器学习能够根据历史上人工审核的情况,学习高水平专家人工审核的经验、手段和结果,首先可以识别出很多不可疑的交易,把它排除,并且帮助人工对可疑案宗进行预排序和分类,根据不同人的能力分配不同的案件去审核。这样可以大幅提高审核效率,降低成本,从而优化资源。这里的机器学习模型就是上文举例的模型,根据历史样本,把它映射成为高维空间的表达式,然后形成模型,从而能够对未知案宗在做同样特征向量的提取后,进行预测和评分,甚至在此基础上,判别洗钱案宗属于什么类型的洗钱。
这套系统能够实现可疑案件的自动排序和分类,达到资深反洗钱专家97%以上的水平,并且这3%的差别,不全是机器学习模型的错误,也包括机器发现的反洗钱专家不能发现的案例,弥补了反洗钱专家的不足。这里的一个关键业务目标的是把非洗钱的案例提前排除掉,节省30%以上的需要人工审核案件数量,并且优化专家资源配置。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号