本文共字,预计阅读时间。
为了传播金融创新典范,推进金融供给侧结构性改革,推动金融业服务实体经济,以及促进实现经济高质量、发展的目的,由北京市地方金融监督管理局指导,清华大学五道口金融学院、清华大学金融科技研究院主办,未央网承办推出“首都金融创新与发展”公开课,邀请金融行业嘉宾分享金融项目的创新模式,以及对行业未来发展前景的深度思考。
在首都金融创新与发展公开课的第四模块“金融科技创新与赋能”中,我们非常荣幸邀请到了得意音通董事长郑方博士做客直播间,带来《“声控”下的无接触金融》主题分享。以下整理来自嘉宾分享实录:
无接触金融与语音的机遇
“无接触金融”本质上是对传统金融渠道的变革,实现线上和线下业务的融合。在经历了物理网点、自助服务电子系统、网络服务三个阶段后,银行已经进入智能化阶段。在这种背景下,语音的机遇在于无监督的身份认证,主要面对两种场景,一种是线下自助,比如在ATM上完成的一些操作;另一种是线上远程,比如远程的开户、审批、转账以及各种相关的交易,这两种情形的共同点在于没有监督,即没有人在其中对你的行为进行监督。中国银联发布的《2018移动互联网支付安全大调查报告》中也显示生物特征身份认证的占比较高并且在提升。而基于生物特征的无监督可信身份认证关注点包括唯一性、安全性、隐私保护、用户真实意愿理解,以及无接触。
今年年初由于疫情爆发,监管部门采取了一些措施,包括暂停使用指纹识别,因为指纹造成的接触可能带来传染隐患,还包括暂缓人脸识别支付商户拓展,因为戴口罩就会使人脸识别的准确率下降从而导致认证风险。这给声纹识别带来机遇。
总的来说,5G催生了全新的应用场景,加上疫情影响,很多线下活动转入线上,海量终端的接入将使“以人为中心”的访问控制安全日趋紧迫。而生物识别技术将重塑身份认证,数字身份将成为人的网上身份证。静态的生物特征,比如人脸、指纹、虹膜等,在隐私保护和真实意愿方面都有缺陷,已经引起了监管高层的重视。而声纹识别的身份验证是生物特征识别和人机语音交互两大类别应用的交集,融合了多种技术,可以通过把声纹的特征与其他特征结合的手段来解决上述瓶颈问题,这也必然是未来的发展趋势和主流,因为语言是人类交流最自然的方式,也必将是人机交互最自然的方式。
声纹赋能金融业的历程
2010年建行的电话银行首次在金融领域使用了声纹识别技术进行声纹认证,2016年建行上线的手机银行同样使用了我们的声纹识别技术,到2018年,央行适时推出了《移动金融基于声纹识别的安全应用技术规范》,是我国金融行业第一个生物识别技术标准,因此2018年也被称为“声纹元年”。2019年市场监督总局和央行联合对外发布了《金融科技产品认证目录 (第一批)》、《金融科技产品认证规则》的公告,声纹识别是唯一的生物特征识别技术产品。2019年得意音通得到了第一张声纹识别领域的认证证书。如果追溯研发时间,其发展历程更为久远。也可以看出,作为监管机构的央行高瞻远瞩,推出《技术规范》,明确生物特征识别标准是技术新、起点高、过程严、范围广和自主性强,并强调其在个人隐私保护和身份认证强度等方面具有一定优势。
金融机构对声纹应用的发展速度很快,已有二十余家银行和金融机构正式上线声纹识别,还有几十家在准备上线。比如建行采用“密码+声纹”双因素认证登录,由于其中声纹本身使用动态密码+声纹,这实际上是三因素,被应用于无卡取款等场景;浦发银行免密登录和转账支付等高安全要求的场景都应用声纹识别技术。
比较典型的声纹赋能金融的场景包括手机银行、信贷风控、反欺诈、用户满意度调查、客服热线、ATM无卡取款和智能柜员机等。有些已经用上了,有一些正在探索。正在探索的新兴场景里,以反欺诈为例,当身份信息丢失后,有黑色产业链会盗取个人信息进行贷款或其他非法活动,此时声纹技术可以帮助解决问题:一方面,将犯罪分子纳入声纹库黑名单;另一方面,对黑名单以外的犯罪分子,如果识别到相同的声纹宣称了多个身份,说明他冒用了别人的身份,因此系统也会拒绝并将其声纹信息纳入黑名单;还有,运用语音识别查找敏感词,比如“车祸”、“住院”,再通过语义分析判断他是否在按照一些脚本诱导或者欺骗用户;运用情感识别捕捉被欺诈的人和恶意欺诈的人的情感变化;利用信号处理技术,当欺诈者通过变声器等手段变声时,去将被掩盖的声纹重建起来,最后找到真正的罪犯。以上这些技术的综合利用,让语音反欺诈成为可能。另一个新兴场景是远程面签,可以通过把人脸和声纹深度结合起来,人脸先对身份进行初步认证,声纹则通过相互交流和问答来强化认证,一旦声纹模型被建立,其认证强度和隐私保护方面的优势就会得以很好体现。得意音通未来的场景是通过一句话解决所有事情,比如“给张三转账100块钱”,在这个过程中既可以识别身份,同时确认用户声音的真实性,即不是合成的声音,并且能够通过语义识别完成任务指令。目前得意音通的原型系统已经完成,经过实验和测试后未来可以推向市场。需要强调的是,一个技术不可能对所有场景都通用,始终需要各种技术结合,最好的起步是将其应用于高频场景。
从声纹到“声纹+”
语音是一维的信号,其形式简单但是内容丰富,包括口音、语言、内容、情感、性别、身份等。声纹是语音信号的信息之一,它兼具生理特性和行为特征。生理特征的最大特点是基本不变;行为特征的最大特点是变化,比如姿势、签名,又比如声纹行为特征,人的声音没有任何两次是完全一样的。声纹将这两个特征结合起来,生理特性使得其识别准确,而行为特征变化的属性给模仿和伪造带来难度,所以声纹是一种很好的、可以利用的生物特征。
声纹识别技术的发展历程从上世纪四五十年代已经开始,而且在过程中经历了很多变化,从最早语音波形语谱到倒谱系数、线性预测系数到特征学习,在模型上,也几乎囊括了所有的模式划分的手段和技术。声纹识别技术有两种分类方法,第一种方法下,分为声纹辨认(N选1)、声纹确认(1:1二值判决)、说话人检出和说话人追踪。第二种分类方法是声纹特有的,因为语音兼具内容和身份等信息的特点,因此根据内容把声纹识别分为三类:第一是文本无关,无论什么语音内容,它都能识别身份,但实现的技术难度很高、现有技术水平下用户体验不好;第二是文本相关,要求说话人必须发音事先指定的文本内容,但可能存在录音闯入风险问题;第三是文本提示,声纹识别系统可以从训练的文本库中随机提取一些词汇、短语或组合,让使用者说或者回答,由于是文本提示的,所以它一定是用户知情和同意的,是可以防止录音重放闯入的。
声音随着人的状态、年龄会发生变化,因此声纹识别技术需要满足这些现实场景的需求,克服鲁棒性(robustness)挑战才能够提供令用户满意的产品。比如环境相关的抗噪音需求和适应戴口罩说话的要求。比如说话人相关的抗时变需求,间隔三个月人的声纹在计算机看来就会有变化,因此为了解决这个问题,得意音通积累了10年的数据库,通过十年来持续对一组人每周的同样内容的话录音,供计算机分析和学习,提取其中不变的特征。比如应用相关的防假冒闯入,一般有直接攻击和间接攻击两种,一个是直接攻击即在麦克风前直接放录音,第二个就是间接攻击,对间接攻击可通过加强软件安全,修复系统漏洞来应对,对于直接攻击,比如说声音模仿、语音合成、语音转换、录音重放,其中录音重放易攻难防,得意音通的“声密保”也已经可以克服。
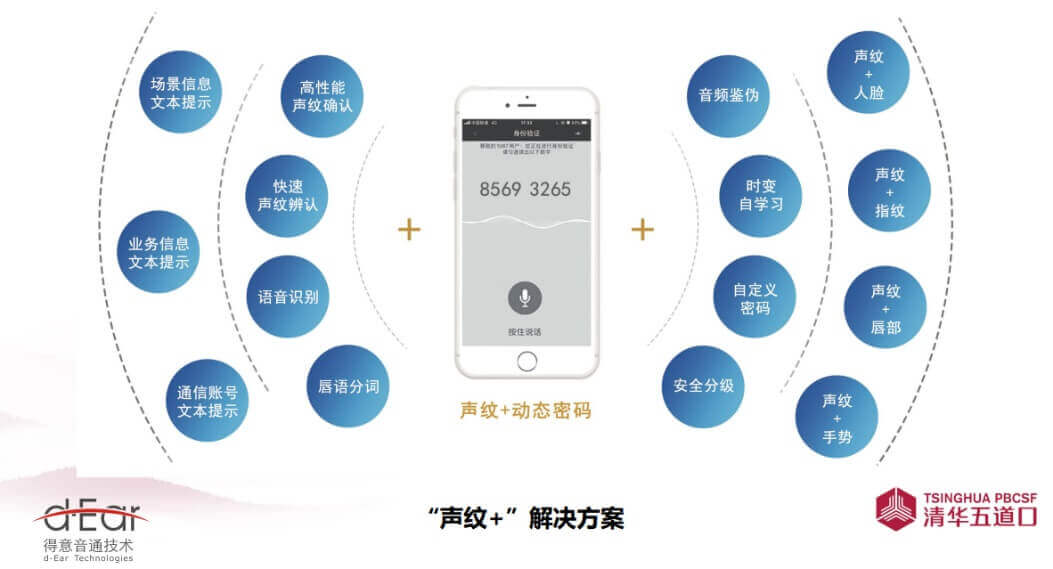
图1 “声纹+”支撑技术和解决方案
从这张图可以看到,当声纹走向“声纹+”后,既解决了准确率问题,又解决了安全性问题、用户体验问题,以及意图理解和情感识别等问题,其所适应的场景就更宽阔、更多样。
清华-得意音通的产学研体系
清华大学在1979年成立语音和语言技术中心,得意音通在2002年成立,清华为得意音通提供技术支持,以知识产权入股,同时得意音通和清华建立了声纹处理联合实验室,并且清华大学人工智能研究院也为得意音通及语音和语言技术中心提供可持续发展的基础性研究成果,因此其间双方关系非常密切,不是简单的混合态组合,而是我称之为的“化合态”产学研体系。清华大学创造国际领先的技术成果,得意音通公司负责产品化,结合市场需求,因此在联合实验室中可以把产品和想法结合起来,提供一个完美的解决方案。
刚刚不久,得意音通上榜2020中国金融科技竞争力100强及2020中国人工智能商业落地价值潜力100强,体现了金融科技和人工智能领域对得意音通声纹识别解决方案的认可。得意音通在录音检测、音频情感识别、声纹时变数据库和防时变解决方案都处于国际领先地位,并且在防录音、声纹自学习能力上都是领先的技术,也是国内首个进入成熟商用的声纹识别产品。现在得意音通的专利也已经走向国际,包括中、日、韩、美等,未来也将进行更多标准化的起草制订工作,并且加强和银行等金融机构的合作。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号