本文共字,预计阅读时间。
为您讲清楚一段数据从一个外部系统进入区块链的全过程。
一笔业务数据在区块链处理的流程大致分为三个阶段:分别是上链前处理阶段、链上处理阶段和智能合约处理阶段。
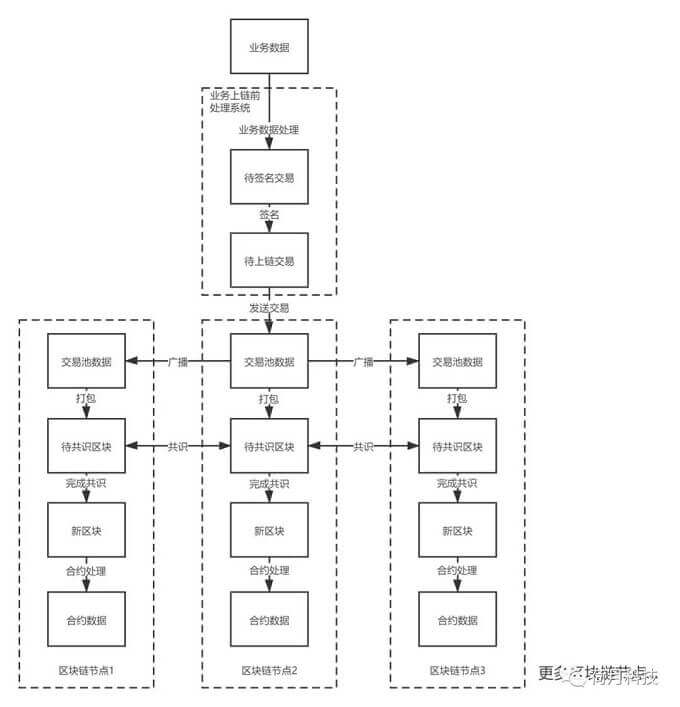
一、上链前处理阶段
业务数据上链前需要将业务数据处理,并且对信息进行签名。这些过程可以通过对应的工具,比如序列化工具和各种椭圆曲线的签名工具来完成,不过更多的时候是通过将各种工具集成的SDK来完成,以太坊的web3就是比较典型的上链前处理的开发工具。
业务数据处理
业务数据可以是任意的内容,比如物流信息、商品交易或物联网设备上传的数据或者对应数据的哈希值等等。这些业务数据既可以通过服务器处理,也可通过物联网设备的边缘计算系统处理。以存证用的物流数据举例,首先对业务数据不需要进一步处理或者简单计算一下哈希值,然后将调用函数的信息加上链数据放入交易结构体的相关部分当中即可。签名前的交易结构体是由链决定的,不过一般都包含调用的合约、时间戳、随机数和调用函数加数据的信息。将签名前的数据拼装好之后,会进一步序列化以便消息传递。对于一些隐私交易,需要用到同态加密或者零知识证明等算法,此时业务数据则需要经过更复杂的加工过程,比如数字经过处理可以变成一个乘方求模的大数或者椭圆曲线上的点,但是拼装和序列化等过程还是相同的处理方式。
信息签名
签名前的数据处理好之后,对该数据进行一次哈希处理,并对哈希进行签名。哈希是与数据绑定的一串值,篡改信息会造成哈希值发生变化,因此本身具有防篡改的特性。接下来是对信息的哈希值进行签名。签名是一种非对称加密的方法,可以在不泄露发送者本身的私钥的情况下,通过公钥和签名信息确认发送者持有对应的私钥。对哈希进行签名还可将发送者的身份和信息绑定,同时也可防止其他人冒充发送者,因此这样处理可保证信息的防篡改的同时认证发送者的身份,防止抵赖。
业务上链前的处理阶段主要是通过工具将业务数据转换成区块链可读的方式,同时通过签名将发送者的身份和发送信息绑定,起到身份认证和防止抵赖的作用,最后再将处理好的信息发送到区块链节点。上链前处理是中心化的,这些处理过程并不涉及区块链节点,因此这一阶段并不需要节点参与。有些系统,如边缘计算系统,本身的性能和储存空间都有限,并不适合做区块链节点,但可以作为业务上链前处理的平台。
二、上链处理阶段
处理完成的数据发送到区块链节点后,就形成了一笔区块链交易并进入上链处理的阶段,链上处理大体可分为交易广播和区块共识流程。
交易广播
在收到交易后,各节点会将接收到的交易先广播到其他节点,以便形成一个统一的交易池来为达成共识做准备。交易广播后联盟链和公链对交易会有不同的处理方法。对公链来说,任何交易发送者都可将交易发送到链上,但是处理能力不是无限的,因此会根据交易的手续费行有选择的处理,手续费低的交易很可能一直无法得到处理。在一些极端情况下,节点为了提高处理速度甚至会出现不处理任何交易的空块。对联盟链来说有一定的准入机制,能够发送交易的应该是合作伙伴,因此处理交易的原则是尽量将能够处理的交易打包进块。
区块共识
区块主要包含区块哈希、区块头和交易数据的信息,其中区块头一般都会包含共识信息、时间戳、区块高度等,并记录前一区块的哈希来指向前一区块;交易数据包含该区块里打包交易的哈希,交易需要根据统一的顺序排序;在确认区块头和哈希之后,就能计算区块哈希。这样通过前一区块哈希和自身哈希相连形成链条,修改链上的任何一个区块的内容会后面区块的前一区块哈希和修改后的哈希不同,因此区块具有防篡改的特性。只有修改该区块和往后所有区块的内容,且每个节点上都以相同方式修改才能完成修改。共识的主要目的就是以某种约定的方式生成能够被大部分节点认可的区块。不同共识方式的区别比较大,但是基本原则就是让不同节点产生相同的区块,尽可能保证数据的一致性。对公链来说,因为节点的通讯状况不可控,保证一直出块的情况下,如果网络出现问题,将可能无法达成一致,甚至出现分叉的情况。对联盟链来说,共识算法需要尽量使节点的区块数据保持一致性,因此在一定数量的节点出现网络问题的情况下将会停止出块。上链处理阶段是将业务数据写入区块的过程,这个过程就是通常所说的上链,这一过程是去中心化的,需要由节点处理。在处理阶段时业务数据还是可以按照发送者的意愿写入不同内容,而进入上链阶段后的业务数据将无法篡改,不过仍然存在上链失败的可能,因此仍需要关注是否完成上链。共识阶段完成后,各节点的区块保持一致。此时的业务数据获得每个节点承认且可追溯的数据了。
三、智能合约处理阶段
上链处理完成后,业务数据已经记录在链上了,对于单纯存证的业务来说,将业务信息写入区块已经完成了这笔业务处理,只需记录存证业务的交易哈希并在取的时候通过交易哈希查询即可。但是大部分业务场景都需要进行一定的逻辑处理,因此通过智能合约处理是必须的。智能合约处理包括合约逻辑处理以及修改状态梅克尔树等流程。
合约逻辑处理
完成上链的业务数据很多情况下需要进一步进行逻辑的处理,比如一次最简单的商品的交易就涉及转账,即买家余额减少和卖家余额增加的逻辑流程,这样的流程虽然可以通过上链前的处理来完成,但是上链前处理是中心化的流程,对网络波动和可信度问题都有一定的劣势,因此通过智能合约进行逻辑处理是比较好的方式。不同链平台对智能合约处理的方式不同,但是和一般的编程语言一样都有调用函数和传入参数的过程。并且因为创建智能合约和调用智能合约的过程都是上链的,即执行的程序和调用的函数与参数都是经过共识的,因此最终调用智能合约的数据的输出结果也是相同的。处理完后的结果会写入合约的状态数据库,这个数据库除了最新状态也会包含历史状态,方便追溯和查询。
修改状态梅克尔树
智能合约的逻辑处理完成后,会修改状态梅克尔树。梅克尔树是一个二叉树结构,不同的叶通过梅克尔树链接到根,能起到防篡改和索引的作用。通过梅克尔树的索引,能够快速定位合约的历史状态,可通过查询某个业务执行的区块高度的合约数据来获取当时的执行结果。智能合约处理阶段是将业务数据进行逻辑处理,并记录智能合约状态的过程,这一过程也需要节点处理。如果合约逻辑处理的操作执行失败,对状态梅克尔树的修改也会撤销,合约的数据将会回滚到调用前的历史数据。需要注意的是合约调用失败和上链失败是有区别的,触发合约调用的时候交易已经在区块里留下记录,而区块是防篡改的,因此调用失败并不会擦除区块里的记录。如果交易因为数据错误或者共识问题而没有被记录进区块,则不会触发合约处理的过程。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号