本文共字,预计阅读时间。
人工智能发展的理想目标,是机器能够像人一样思考,并与人正常沟通交流,在某些领域,甚至可以超越人类,为人类提供更好的服务。
就像硬币有两面一样,人类也有智慧和愚蠢的两面性。如果AI 真的“类人”的话,是不是也会有智慧和愚蠢的两面性呢?不知道这算不算一个“玄学”问题。
不管怎样,人工智能技术,以日新月异的速度在飞速发展,每年各种新技术、新名词、新场景层出不穷,让关注这个领域的人目不暇给,疲于应对与理解。
我们可以先看一下这几年的技术迭代趋势,对很多人来说,还没弄明白机器学习与深度学习之间的关系,紧接着是强化学习、生成对抗网络(GANs),迁移学习……
那么,2020年,需要重点了解哪些“X学习”领域呢?
从价值落地的实际需求来说,东方林语列出了需要重点关注的三种有价值AI技术:图学习、自监督学习、联邦学习。
我们的口号与目标是,尽量以不带公式、函数,以说人话的方式讲明白这些高大上的概念。
一、基于知识图谱的图学习:
自然语言领域的顶级盛会ACL2020,2020年7月10日已经落下帷幕。著名计算机科学家Michael Galkin,从问答系统、知识图谱嵌入、自然语言生成、人工智能对话系统、信息提取等方面总结了知识图谱的最新工作,如果用一句话来概括就是:
知识图谱展现了更好地揭示其他非结构化数据中的高阶相关性的能力。
知识图谱分为通用知识图谱与行业知识图谱。
通用知识图谱,是以百科类知识为主,强调知识的广度,数据来源一般较为单一,比如我们常用的搜索引擎,就是通用知识图谱。
对于企业而言,行业知识图谱更有价值,它是面向专业领域的专有应用,基于每个行业的知识来进行构建(比如金融、电力、公安等)知识库,以知识的深度为特性,数据来源则更为丰富。
以金融知识图谱来说,它就是一种用图模型来描述知识和建模实体之间关联关系的技术方法,旨在从金融机构内、金融机构外数据中识别、发现和推断企业、企业自然人、行业、事件、产品等实体与金融机构业务之间的复杂关系,是实体关系的可计算模型。
基于知识图谱打造的智能中台,可以将“企业、个人、机构、账户、交易、票据、行为...”等打造出超大一张图,运用复杂网络、图计算、图神经网络等前沿算法,实现企业内外部多源异构数据的关联与探索,全面赋能对公、零售、信用卡、稽核营销等各业务条线。而实现的诸如隐含关系挖掘、多层级关联等功能,是传统数据库下,采用传统数据挖掘方法无法实现的,因而,得到了越来越多的认可。
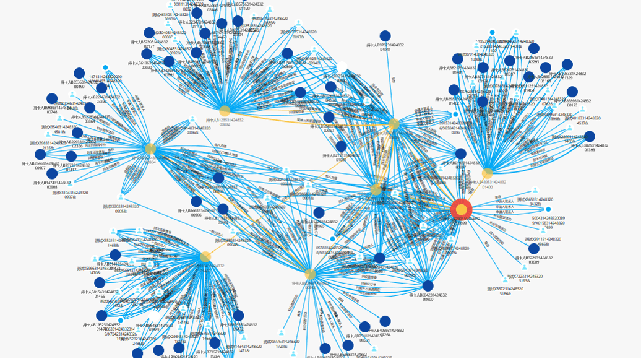
通过知识图谱技术,可以将多源异构的大数据整合成机器可以理解的知识,将“单点”的身份、资料等的核查转换成从“面”的形式进行欺诈风险检测,从而实现欺诈的识别与防御。通过知识图谱的方式把实体(包括持卡人、非持卡人、单位、商户等)之间的隐含关联关系挖掘出来;基于已有的知识图谱进行更为深入的知识推理,分析探究个体的影响方向、影响范围、影响深度等重要维度,有效预防团伙欺诈风险,提高分析的准确性。对整体的信用卡运作中涉及到的营销、贷前、贷中、贷后、催收等流程提供决策辅助,如潜在优质客户挖掘、风控管理、催收失联修复等。
另外,还可基于用户行为分析进行模型的个性化排序,并进行基于知识抽取、内外知识融合的智能检索,进行精准答案定位与溯源,全面赋能各业务系统与组织中的个人。
比如,建行、招行、光大银行、广发银行、广东农信等四五十家金融机构,已经充分发掘出了知识图谱的价值。
作为企业级中台能力建设的重要组成部分,夯实企业的数字化转型和AI能力腾飞的基石,基于知识图谱的图学习,已经证明了这种技术的价值与前景。
下面是艾瑞咨询的一个知识图谱能力图,可以参考一下。

二、自监督学习
近几年人工智能的火热,很大一个原因,就是深度学习技术的革命性突破。
尽管深度学习在人工智能领域做出了巨大贡献,但训练需要依赖大量数据,并消耗大量硬件资源。因此,除了“黑箱”运算的不可解释性,减少深度学习的数据依赖性也是目前最重要的研究方向。
另外,目前取得重大价值的AI场景,深度学习算法很大程度上是基于监督学习模型,比如目前取得比较广泛应用的视频与图像识别分类工具,面部识别系统,语音识别系统等等需要在数万、数十万、甚至百万个带有标签的示例中进行训练,才能取得比较好的成果。
过去几年中,强化学习征服了很多人认为不可能的一些高阶人工智能的游戏,比如人工智能程序已经陆续征服了”围棋”领域的世界冠军、游戏《星际争霸2》、《DOTA2》等的人类世界冠军,深度强化学习在游戏和模拟中证明了它的价值。
尽管强化学习、迁移学习、无监督学习等学习算法也受到了很高的关注,但其应用价值与场景还是有限,探索更多价值落地,还有漫漫长路要走。
这种背景下,如何摆脱对数据与标签的高度依赖,是人工智能在“明天”能否取得更大价值的关键研究方向了。
正是在这种背景下,“自监督学习(Self-supervised learning)”的概念,被提了出来。
自监督学习的思想理念其实很简单并通俗易懂,简单来说就是:
即使输入一堆无监督的数据,但是通过数据本身的结构或者特性,构造标签(pretext)出来。有了标签之后,就可以类似监督学习一样进行训练。

自监督学习可以被看作是机器学习的一种“理想状态”,模型直接从无标签数据中自行学习,无需标注数据。如果这种技术可以取得规模化价值使用,在数据清洗、打标签等“苦力”工作,将会取得实质性、革命性飞跃与替代。
“有多少智能,背后就有多少人工”这样的说法,就会逐渐销声匿迹了。因此,学术界一直有这样的一种语言:自监督方法在深度学习中将取代当前占主导地位的监督学习方法。
未来,想要用深度学习的方法来构建达到人类智能水平的人工智能,最关键的一点是什么?
关于这个问题,在2020年的 ICLR 大会上,深度学习领域三巨头里的两位约书亚·本吉奥(Yoshua Bengio)、杨立昆(Yann LeCun)在谈到深度学习领域里的研究趋势时都表示,自我监督学习可能会让 AI 在推理上更像人类。

人类学习的大部分知识和动物学习的大部分知识都是在自我监督的模式下,通过观察世界,并与之进行一些互动,来实现学习与进化的。
监督学习需要在标记的数据集上训练人工智能模型,随着自监督学习的广泛应用,监督学习的作用将越来越小。自监督学习算法不依赖注释,而是通过暴露数据各部分之间的关系,从数据中生成标签,这一步骤被认为是实现人类智能的关键。
按照大神Yann LeCun的说法:
“如果说人工智能是一块蛋糕,那么自监督学习就是其中的主要内容。”
“人工智能的下一轮革命将不会受到监督,也不会得到纯粹的加强。”
三、联邦学习
人工智能领域,另外一个关注的焦点就是:数据隐私保护。
欧盟GDPR(General Data Protection Regulation,通用数据保护条例)是隐私保护领域最为权威和细致的立法,被称为“史上最严个人数据保护法”,旨在通过约束信息处理行为,赋予公民对其个人数据更大的控制权,另外,我国也相继出台了《网络安全法》等法律法规,加强了对个人隐私保护的立法与治理工作。
因此,降低数据获取成本的同时,如何更好的保护用户隐私,也是人工智能领域最重要的研究方向。
这种背景下,“联邦学习FederatedLearning”的概念就横空出世了。联邦学习的主要理念,就是要做到在用户不对外共享数据的前提下,完成传统人工智能技术无法实现的多机构联合训练模型系统。该概念,是2016年由谷歌率先提出的。
联邦学习主要采用了同态加密的技术来保护多方数据隐私,可以根据用户的特征维度和样本ID的重叠,可以分为横向联邦学习和纵向联邦学习,亦或在两者重叠度都很低的情况下采用联邦迁移学习。
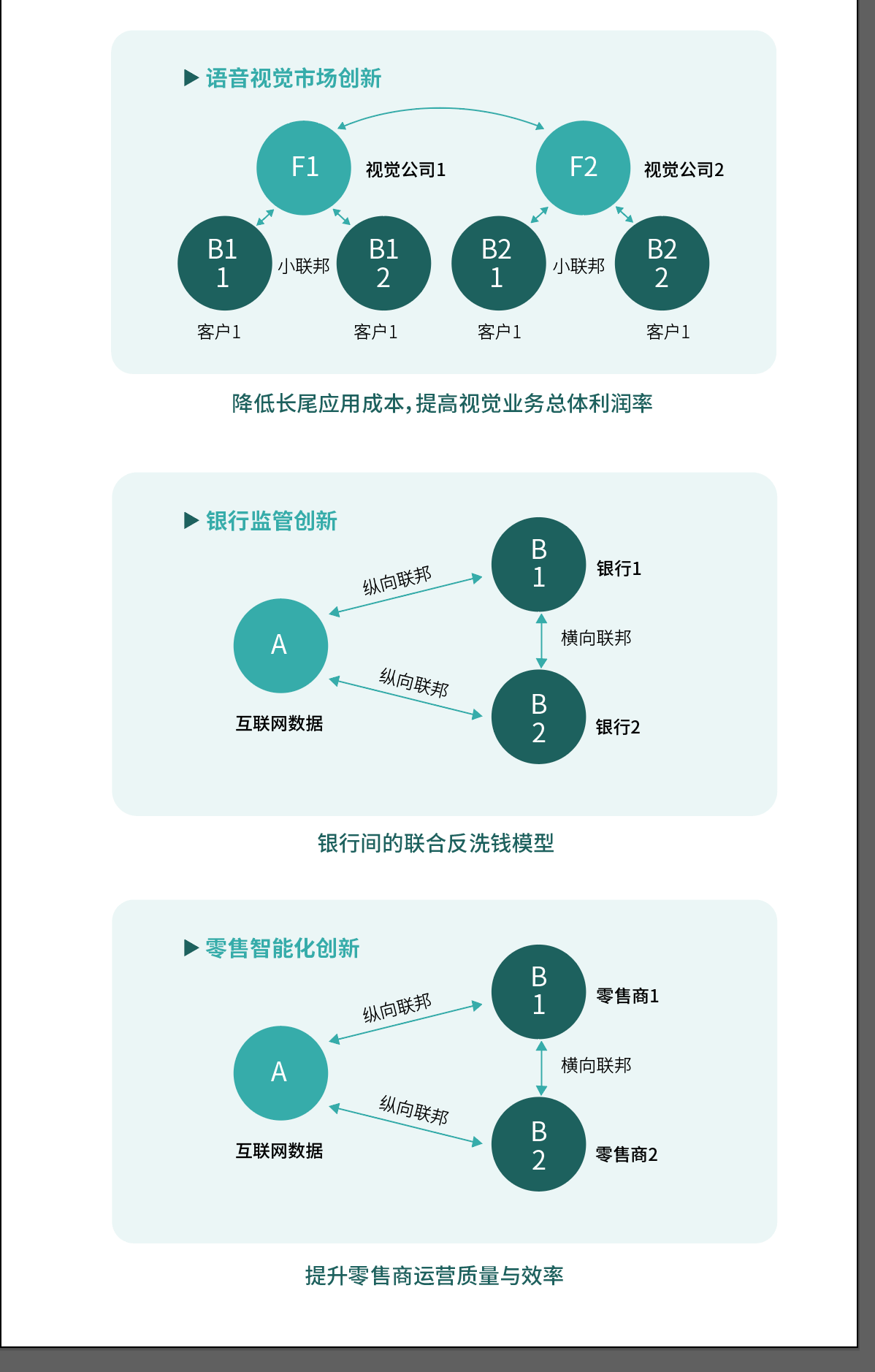
其目的是为了在保障企业提升AI数据治理能力和可用性的同时,同步加强AI应用中的数据安全与可靠性。
目前,在一些领先的金融机构,比如平安、微众银行等,已经取得了价值应用。
四、三种学习的总结
如果分别用一句话来总结其特点,可以概括如下:
-
基于知识图谱的图学习,是从感知智能迈向认知智能的关键技术;
-
自监督学习,是让机器自动构建标签并自动学习的关键技术;
-
联邦学习,是保证机器学习效果的同时,也同步保护用户隐私的关键技术。

未来1-3年,图学习、自监督学习、联邦学习,将是人工智能领域的三个重点方向,也是人工智能在更多场景取得更大价值的重要“技术载体工具”,我们可以保持充分的关注、了解与学习。
为了让大家更直观、高效的理解人工智能价值及应用全流程场景,东方林语近期推出了“人工智能扑克牌”系列互动文章与课程培训。欢迎留言咨询,与东方林语一起学习进步。
参考资料:https://venturebeat.com/2020/05/02/yann-lecun-and-yoshua-bengio-self-supervised-learning-is-the-key-to-human-level-intelligence/
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号