本文共字,预计阅读时间。
文/TalkingData 耿舒天
(本文为“2020金融文字节——银行数字化创新主题征文大赛”投稿文章。)
随着技术的革新,金融行业的新模式、新业态不断涌现,对公共安全和社会治理也提出了诸多新挑战,如何有效管控这些新模式、新业态,使其朝着正确的轨道稳步前进,是摆在行业和监管部门面前的共同难题。近年来,数字金融行业呈现出涵盖广、多元化、增长迅速的特点;与此同时,也有部分欺诈者利用技术、监管和公众意识等方面的不完善,演绎着千变万化、层出不穷的欺诈行为。攻坚战迫在眉睫,数据是排头兵。本文将结合实例,对行为数据在线上消费信贷反欺诈中的应用,进行简要的介绍与探讨。
一、“握不住的沙”:银行反欺诈工作面对移动端诈骗的猖獗攻击
数字技术与金融的融合,以及金融科技的发展和其对传统金融行业的渗透正成为一种不可逆的潮流,金融行业新模式、新业态不断呈现。金融科技的应用大幅降低了金融领域的信息不对称性,为健全多层次金融市场做出极大贡献。然而这样的融合也是一把双刃剑,技术在创造便利的同时,也带来了风险——利用技术手段的新型金融欺诈变化多端、如影随形。金融欺诈行为已呈现出高频化、产业化、隐蔽化等新特征,对传统的反欺诈手段形成极大挑战:
- 高频化:移动终端是众多消费信贷业务的流量入口。每年,全球针对移动端的诈骗攻击增长率约为24%;其中,消费金融坏账的损失超50%都源于金融欺诈;
- 隐蔽化:移动端便捷、高效,但隐匿性强、难于追踪,已成为滋生欺诈的“温床”;
- 产业化:欺诈行为已越来越群体化:专门设备、专业团队、专人设局、专人销赃,形成有组织、成规模、分工明确、合作紧密、协同作案和“黑色产业链”,从业人数超150万。
很多业内人士感慨:“信用风险尚且可控,欺诈行为却防不胜防。”
因此,针对金融领域的反欺诈技术也应不断革新,既要精准打击存在的风险,也要执棋先行,做到防患于未然。
二、“剑走偏锋”:行为数据对反欺诈模型的加持
大数据技术,使得更具前瞻性和精准性的反欺诈手段成为可能。而其中的行为数据具有体量大、直观性强的优势,但因其不是传统的“数字”形式,一直以来都是一片很容易被忽略其价值的领域。实际上,相较于传统手段,行为数据可作为有效的补充对反欺诈流程和规则形成“加持”。运用行为数据重构线上反欺诈方案,优势明显:它能够覆盖营销、贷前、中、后四阶段,运用数学、统计学以及人工智能的方法,精确识别异常行为。
(一)流程优化

图表 1:行为数据反欺诈对整体反欺诈工作的流程优化
行为数据可作为前置“锋线”,以更为直观、更易理解、更高速快捷的方式,对交易方是否涉嫌欺诈进行快速筛选,从而在大大提高效率的同时,也有效提高预测精度。
(二)规则优化
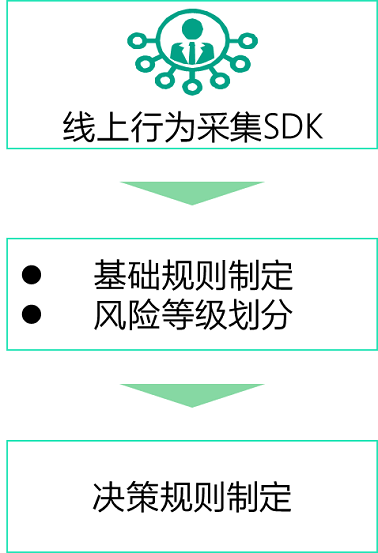
图表 2:行为数据反欺诈对整体反欺诈工作的规则优化
以行为变量为基础设计反欺诈策略的主要工作,一是基础规则的开发和规则风险等级划分;二是决策规则开发,以对整个风控策略形成一定补充,更早地识别客户风险水平。通过设备埋点,获取和积累大量线上交易行为数据;经过脱敏清洗与整理,将特征行为进行标准化提取,设计反欺诈策略;当设备行为反欺诈策略运营一定时间后,积累了一定客户数据和欺诈表现,即可开发反欺诈模型并制定评分规则,优化设备行为策略。
这一方案设计的大前提是,“事出异常必有妖”——认为在欺诈过程中,一定存在异于常人的行为,且能够被清晰捕捉。例如,输入用户名密码时的按键行为——第N个按键按下与弹起的时间(按键时长);2个按键之间间隔时长(移动距离);误按漏按行为模式;明显变慢/犹豫-明显变快/按键使用手指边缘;使用其与历史纪录的偏离度作比较、打分等。再比如,根据登录时间、上网环境等判断——如果一个用户总是在东八区的凌晨三点频繁登录进行交易,那欺诈的可能性就会比在正常作息的用户高。
三、“初露锋芒”:实战中的反欺诈策略设计
(一)数据获取
基于行为数据的反欺诈方案设计的基础是用户行为数据的积累,在实践中通过设备埋点获取。
对基于用户行为的数据平台来说,发生在用户界面的、能获取用户信息的触点就是用户数据的直接来源,而建立这些触点的方式就是埋点。当这些触点获取到用户行为、身份数据后,会通过网络传输到服务器端进行后续的处理。
从准确性角度考虑,埋点分为客户端埋点和服务端埋点。客户端埋点,即在客户操作界面中,当客户产生动作时对其行为进行记录,这些记录只会在客户端发生,不会传输到服务器端;而服务端埋点,则通常是在程序和数据库交互的界面进行埋点,这时的埋点会更准确地记录数据的改变,同时也会减小由于网络传输等原因而带来的不确定性风险。
通过埋点,我们能够获取账户注册、认证行为、登陆行为、借贷申请行为、网络信息等五大类信息,经过加工形成变量,为后续策略设计提供了大量数据基础。
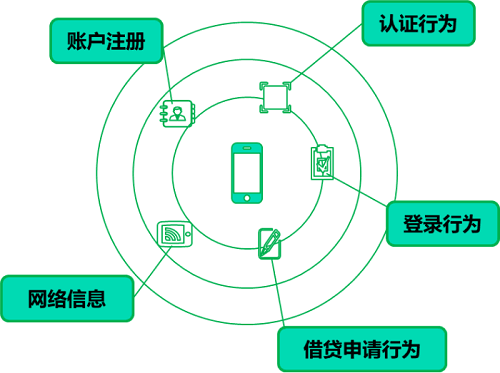
图表 3:埋点收集信息的维度

图表 4:埋点信息和加工变量列表(部分)
(二)策略设计
这一步是整个方案设计的重中之重,需要将具象化的、各异的行为数据进行抽象化、总结性、标准化的清洗和描述,综合数学、统计学、网络工程学、生物学、社会学等多学科知识,结合专家判断,进行量化研究和策略设定。
下表是一个示例:

图表 5:反欺诈规则列表(部分)
策略提取后,还需对各规则进行具体量化设计,设定阈值,并综合运用聚类分析、AHP等统计学方法,对规则进行“高中低”不同风险等级的分类,在实际运行中不断校正,为后续模型构建和决策建议设计做准备。
(三)模型构建和决策建议
当设备行为反欺诈策略运营一定时间后,积累了一定客户数据和欺诈表现,即可开发反欺诈模型并制定评分规则,指定标准评分,优化设备行为策略。
(四)模型校验
在本次实例中,采用KS值对模型进行评价,KS值越大则表示模型能够将正、负客户区分开的程度越大,通常来讲KS>30%即表示模型有较好的预测准确性。此次模型KS值为41.19%,说明好坏样本区分度高,模型效果良好。
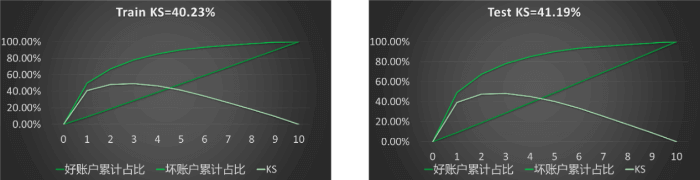
图表 6:反欺诈模型校验结果
(五)实战效果
经过行为数据加持,反欺诈模型区分度较原有策略提升50%以上,运行一段时间后,新客户坏账率下降30%,充分体现了行为数据在线上消费反欺诈应用中的价值。
四、结语
从基于大数据的金融反欺诈的实践经验来看,反欺诈之战不是某一种技术或方法的单打独斗,而是一场集数据、技术和机制于一体的综合防御战。其中,数据是反欺诈体系建设的核心和根基,技术是打赢反欺诈之战的重要支撑,机制是优化反欺诈效果、提升反欺诈能力的重要保障。行为数据的应用,为大数据风控领域开拓了一条新的思路,合理高效应用行为数据,能够进一步夯实“数据”这一反欺诈体系建设的核心根基。“路漫漫其修远兮,吾将上下而求索”,只有立净化行业之志、举全行业之力,在反欺诈体系建立上加强合作、信息共享、共防共御,良性健康的数字金融生态圈才能逐步形成。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号