本文共字,预计阅读时间。
我国数字经济步入深化应用新阶段,激活数据要素价值潜能是做强做优做大我国数字经济的战略所需和关键所在。以数据开发利用为抓手激活要素价值,是金融科技行业面临的重大命题,也是当下金融科技先进企业需要探索突破的前沿领域。
在数字科技的浪潮下,我们正处于一个充满机遇和挑战的新时期。数据资源的海量化、多元化,为我们在金融风控业务上进行科学决策提供了有力的保障。丰富的数据要素无疑是一笔巨大的财富,可以帮助我们更好地洞悉客户行为,优化风控策略,提高业务效率;与此同时,也带来了挑战:如何在特定建模任务下迅速排除噪音数据找到有效的样本?在风控模型领域中,如何从海量的样本中精准地挑选出最有代表性的样本,从而构建出针对特定客群的风控模型?
这是复杂但又非常有价值的实践问题,在客群数量较多样本量级较大的情况下,基于成本和效率的考量,我们不会通过穷举的方法去寻找最佳的样本组合,但如果选择不当,就可能会导致模型预测出现较大的偏差,从而影响到风控的效果。
本文针对样本组合选取中的主要分组依据,进行概括性分享。
样本组合的策略具体来说有一种行业中常见的方法,从业务属性这个视角来观察样本客群,基于业务经验判断是否适合组合。但是从占融的多年的创新实践来看,我们发现还有两种同样重要却常被忽视的切入视角:即模型交叉验证视角和聚类分析视角。更为行之有效的方法,是基于三个不同的视角来观察和分析样本客群的相似性,从而针对不同的建模任务以选取合适的建模样本。
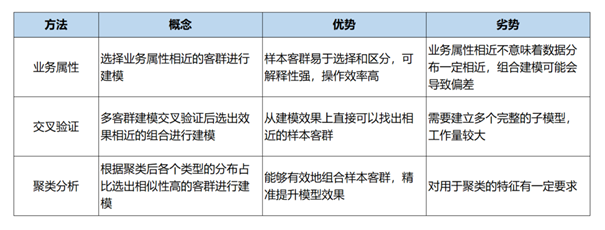
图1:三个不同方法的分析
从行业中业务视角来看,着眼于样本客群的业务属性,将业务属性相近的客群进行组合建模,是业界较为常见的样本组合策略。就实际建模而言,比较重要的业务属性有:利率(IRR5、IRR12、IRR24、IRR36),场景(贷前、贷中、贷后),客户(新客、老客),产品形态(消费贷、现金贷、场景贷),件均额度,流量渠道等等。金融信贷业务当前仍在不断地发展,所以业务属性的分类和取值也要紧跟业务实际情况来进行定义,不必局限于本文。从实践经验来看,不同业务属性样本客群的特征分布差异较大,当属性相近的样本客群组合起来建模时,相比单客群建模往往会有所增益。

图2:一笔业务订单部分属性的信息详情
从交叉验证视角观察,关注的重点在于样本客群在模型预测层面能否互相产生增益。主要方法是使用不同的样本客群分别构建模型后,再利用这些单客群模型分别对不同的样本客群进行预测评估,从而找出相似的样本客群。
举个例子,假设我们现在有N个不同的样本客群,分别为客群1、客群2、… 客群N,然后我们使用单一客群的样本来建立模型,从而得到模型1、模型2、… 模型N。接着让N个模型对这N个客群的测试集进行预测,算出KS、AUC或其他评估指标的取值,从而得到一个N X N的交叉评估矩阵。通过这个矩阵,我们可以明确地看到,哪些客群的模型跟自身客群模型的效果更接近,从而判断模型背后的样本客群共同建模更可能产生增益。多客群多模型交叉验证是一种评估模型预测能力和泛化能力的重要手段。
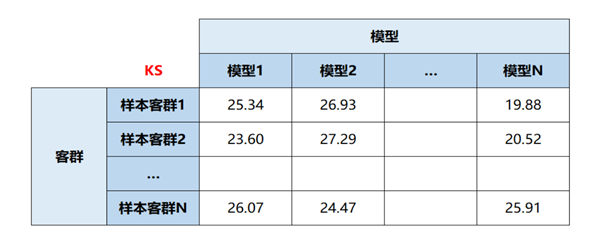
图3:一个各客群模型交叉验证的图表
从聚类分析的视角出发,利用一些区分能力较强的特征数据对不同的样本客群进行无监督聚类,然后通过分析各个样本客群中的聚类类型的占比分布,以此来理解不同样本客群的特点。对于那些聚类类型的占比分布相似的客群,我们可以考虑将这客群在建模时理解为相似的样本客群进而组合在一起。
在具体的实践中,首先从所有客群样本中分别提取出好样本和坏样本,好坏的定义取决于建模任务的标签。然后,我们为这些样本匹配上IV或KS相对较高的特征,或者是外部数据源。接下来,我们基于这些特征分别对好坏样本进行聚类,假定分为10个聚类类型,类型名称为0-9。聚类完成后,就可以观察每个样本客群的好坏样本中,类别0-9的占比分布情况。最后,我们对每个客群中好坏样本的聚类占比分布进行分析,占比分布相近的客群可以考虑作为建模样本组合起来。过往诸多经验证明,这是一种非常有效的样本组合手段。
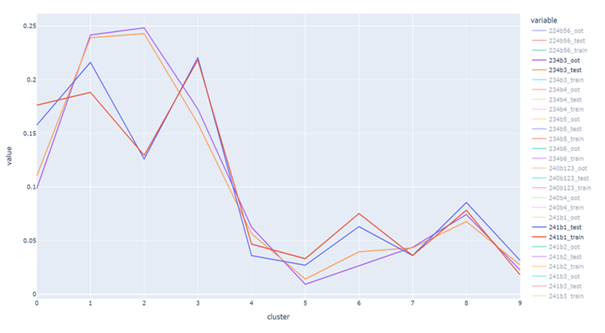
图4:一个聚类分析中各类型占比分布的折线图
需要说明的是,在占融数科的实践过程中,这三种分析样本的视角的并不是孤立的,而是相互结合使用,形成一个相对全面的视野,为实际的建模工作提供指导。
具体来说,首先,我们要考虑的是业务属性视角,因为它直接关系到我们的业务需求和业务场景,也是选择样本的基础。然后,我们会结合模型交叉验证视角和样本聚类分析视角,通过数据和模型的角度,更细致地观察样本之间的相似性,进一步优化我们的样本选择。
从KS效果上看,占融数科的结论是这三种方法的结合使用,比单独使用任何一种视角都要更有效,三者结合使用来建模,比业界常用的业务视角建模要高3-5个点。单独的视角可能会忽视一些重要的信息,而结合使用则可以充分利用所有的信息,使我们的模型更加准确、高效和稳定。当然,也会出现不同视角给出的结论可能会有所不同的情况,在这种情况下,我们会根据实际进行权衡,以实践结果为准绳,通过科学的建模实验来进行校验。例如,如果业务属性视角和模型交叉验证视角的结论不一致,我们会控制样本变量,设计多个不同样本组合的建模实验进行对比分析,观察模型实际的效果,最后选择效果最好的样本组合。
以实际落地项目为例,占融数科曾与某头部互联网大厂进行信用风险分的联合共建,由我方提供建模样本,互联网大厂提供建模特征。占融的建模目标是将这个信用风险分,打造成在IRR24利率客群上有强大信用风险区分能力的产品。为了实现这个业务目标,我们首先从业务属性视角出发,在样本库中找出所有24利率类型的样本客群,由此形成了一个广泛的样本组合,我们将其称为组合A,客群数量为N。然后,我们对N个样本客群分别建模再进行交叉验证,从N X N的交叉验证结果分析,存在两个客群X和Y的建模效果跟其他客群建模效果差异较大的现象,所以在组合A的基础上,将两个客群分别和同时去掉,形成三个不同的客群组合,称之为B1(排除X)、B2(排除Y)、B3(排除X和Y)。接着,将组合A的样本客群跟重要的建模特征匹配后进行聚类,设定10个不同的类别,分别观察组合A中不同客群在不同聚类类别上的占比差异。我们发现,存在一个客群X的占比分布跟其余客群的分布差异较大,可以看出客群X在交叉验证和聚类分析两种不同的方法中互相印证,都应该排除。最后我们对所有的样本组合进行建模,发现组合B1的KS效果最好,相比A而言KS提高了3个点,这个结果也验证了我们的分析样本的视角是完全可行的。模型上线后,在实际的线上调用中,模型的预测效果也十分出色,在24利率的客群上表现优异,为合作机构在信贷决策上提供了助力。
总体而言,在金融信贷行业中,风控模型的应用场景多样,样本数据多元。在既定的建模目标下,探索最优的建模样本客群组合是一个需要不停实践、不断思考的过程。实践证明,在建模的过程中,从多个不同的视角来分析样本客群的异质性和同质性,可以极大地帮助我们选取到合适的样本客群。多维度的思考和实践,才能构建出真正适应特定任务的风控模型,从而精准地提升模型的识别效果,为金融信贷决策提供更有价值的参考。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号