本文共字,预计阅读时间。
导读
在大语言模型研发向可控的模块化开放体系转变的趋势中,Meta以开源框架为核心策略,推进了LLaMA系列模型发展。从LLaMA 1的学术应用,到LLaMA 2的商用开放,再到LLaMA 3的多语言支持、32K长上下文窗口及接近GPT-4 的性能提升,直至LLaMA 4采用混合专家架构、支持多模态能力及行业领先的上下文窗口实现技术突破,Meta通过透明的训练机制、灵活的部署方式和高效的推理性能,在GPT-4、Gemini等主流闭源模型主导的行业格局中,为开源生态提供了重要支撑,推动AI产业走向更具普惠性、协作性的发展新范式。
【 中国金融案例中心 文:叶子、谢彬彬 编辑:谢彬彬 】
Part 1 公司简介
1.1 Meta公司概况
2013年,Meta Platforms, Inc.(原Facebook)开始在人工智能基础研究领域持续投入,组建了FAIR(Facebook AI Research)实验室,聚焦大规模预训练模型、图神经网络、多模态交互等底层技术研发。与OpenAI、Anthropic等以闭源为主的开发策略不同,Meta始终强调"科研导向"与"开源共享",相继推出了PyTorch、FAISS、DINO等深具影响力的工具,为整个AI社区提供基础支撑。
大语言模型成为主流后,Meta明确提出以开源大模型构建"全民可用的基础模型",其战略重点在于性能可控、结构透明、可广泛微调,而非端到端商业封闭生态。LLaMA(Large Language Model Meta AI)系列即源于这一路线,其核心目标是降低AI研发与部署门槛,使中小型组织也能获得高性能语言模型能力。截至2025年4月,Meta的LLaMA系列已成为全球下载量最高、社区使用最活跃的开源大语言模型之一,并被集成于数百个学术项目、创业平台和AI产品之中。
表1 Meta公司及其大语言模型发展时间轴(2013-2025)
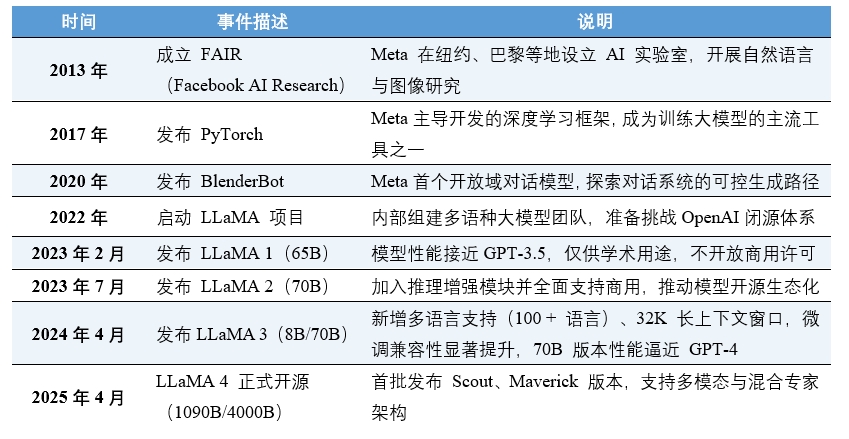
(数据来源:Meta AI Blog、FAIR 官网、LLaMA Whitepaper等)
1.2 LLaMA模型概述
随着GPT-3/4与Claude等闭源模型能力不断提升,AI能力日益集中于少数几家科技巨头。Meta意识到,这种技术垄断不利于模型体系的长期发展,特别是在科研和本地私有部署领域,对"透明、可研究、易微调"的模型需求急剧增长。
在此背景下,2022年Meta启动了LLaMA项目,并于2023年2月发布了首代模型LLaMA 1。该版本强调"相同参数规模下的效率最大化",在65B规模上已达到GPT-3.5的语言理解能力。同年7月发布的LLaMA 2在性能优化的同时正式向商用开放,奠定了开源模型的产业化基础。
2024年4月发布的LLaMA 3是Meta开源路线的关键里程碑。该版本在多语言处理(支持100+语言,非英文语料占比28%)、长上下文推理(最大支持32K token窗口)和微调效率(支持LoRA与QLoRA量化)上实现突破,70B版本在MMLU等基准测试中得分超85%,首次逼近GPT-4的水平。LLaMA 3的训练稳定性与推理速度较前代提升了20%,成为企业级私有部署的首选开源模型。
2025年4月,LLaMA 4正式发布,其在LLaMA 3的基础上采用混合专家(MoE)架构,支持文本、图像、语音的早期融合处理,并首次实现超大规模上下文窗口(最高 1000万token),在推理效率与商用适配性上实现了跨越式突破。
表2 LLaMA系列模型特点
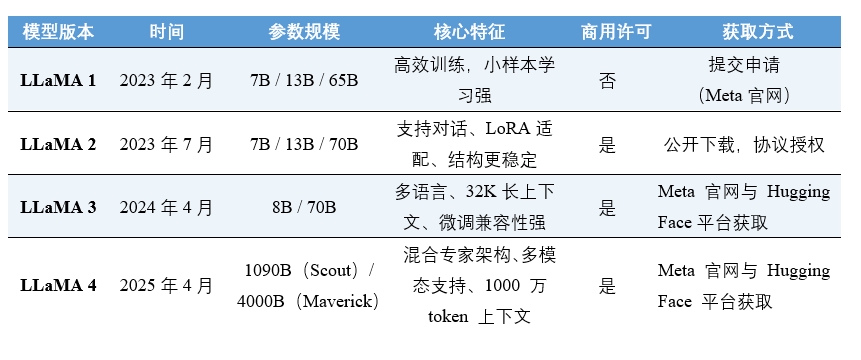
(数据来源:Meta AI Research, Hugging Face LLaMA Collections, LLaMA 3/4 Technical Reports)
Part 2 市场定位与产品战略
2.1 市场定位:模态生态中的中高性能开源支点
LLaMA 4在大模型市场中的定位,并非如GPT-4或Claude 3的API产品服务,而是一种支持多模态输入、成本可控、适配灵活的基础能力资源。在性能表现上,LLaMA 4的Maverick版本(4000亿参数)在多项多模态基准测试中已超越GPT-4与Gemini 2.0,但其运行支持在主流GPU(如 NVIDIA H100)上独立部署,无需依赖专属云平台。这种特性使其更贴近工程应用场景,而非终端用户交互。
在闭源模型中,用户几乎无法接触到模型内部结构,更无法进行二次调用。以OpenAI为例,其模型能力虽强,但用户必须通过API访问,无法自主控制生成过程,也无法优化模型对特定任务的表现。LLaMA 4则提供了完整的模型权重和训练接口,支持开发者根据自身需求进行微调。例如,Scout版本(1090亿参数)可在单卡H100上运行,适合代码库推理与文档摘要任务;Maverick版本(4000亿参数)支持视觉/语音输入,需多卡服务器部署,适用于复杂多模态应用。
表3 LLaMA 4与主流模型的差异化定位
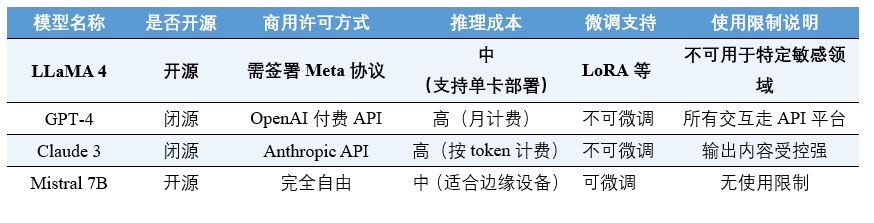
(数据来源:各模型发布说明书与产品页)
2.2 目标客群:科研、创业与企业内化需求者
LLaMA系列模型的定位,并不面向终端消费者或内容创作者,而是明确指向开发者、研究人员以及需要私有部署的企业技术团队。对高校和研究机构而言,Meta所提供的模型权重、结构定义和训练细节,为学术研究和验证实验提供了高度透明的起点。许多自然语言处理课程、研究课题和基础能力评估实验,已将LLaMA 纳入教学与科研体系。
对于AI创业公司来说,LLaMA的价值则更具实用性。与依赖闭源API的大模型不同,它具备本地运行、可控微调和部署成本低等优势,尤其适合快速原型开发和定制化需求。在中大型企业场景中,LLaMA同样展现出明显优势。金融、医疗、政务等领域,通常对数据隐私、安全监管有严格要求,无法将信息流经第三方云平台。LLaMA所支持的本地部署方案,恰好满足了这类行业对"模型不出境、数据不外流"的底线要求,成为"自主智能能力建设"中的重要一环。
2.3 使用规则:有条件的开源许可机制
尽管LLaMA被归类为开源模型,但它并未采用Apache 2.0或MIT这类完全自由授权的协议。Meta对其商用使用设置了一定边界。在不涉及商业用途的研究环境中,用户可直接使用LLaMA模型进行测试和探索。然而,一旦模型被集成进SaaS工具、客户端应用或商业产品中,便需要申请Meta商用许可。这种策略介于"完全开源"与"商业闭源"之间,强调的是"可控可监管"。
具体来说,Meta在许可协议中明确禁止将LLaMA用于军事用途、人脸识别、大规模监控和违法违规内容生成系统。同时,Meta也保留了对违反条款使用行为进行法律追责的权利。用户在使用模型前需确认其用途符合协议规定,并对部署后的内容风险承担主体责任。这种开放但受限的治理方式,在开源大模型中属于相对稳健的路径,也体现出Meta对大模型使用伦理问题的重视。
Part 3 技术架构与核心能力
LLaMA系列模型不仅是为了追求"更大"的参数量,而是希望在开源的前提下实现更高效、可控的大语言模型。LLaMA 4作为Meta首款混合专家(MoE)架构的开源模型,在训练数据、多模态处理、推理效率等方面均实现了突破性升级。
3.1 混合专家架构与多模态能力
LLaMA 4首次采用MoE(Mixture of Experts)架构,每个模型包含多个并行子网络("专家"),通过动态路由机制为不同输入分配最优专家处理。以Maverick版本为例,其包含128位专家,总参数达4000亿,但每次推理仅激活170亿参数,在保持高性能的同时降低计算成本。
前代LLaMA 3为LLaMA 4的多模态能力奠定了一定基础,首次实现了跨语言长文本的结构理解。其采用标准Transformer架构,通过改进的tokenizer和多语言数据配比,显著提升了跨语言长文本的处理能力。而作为原生多模态模型,LLaMA 4采用早期融合技术,将文本、图像、语音的token在输入层整合,支持跨模态关联推理。例如,输入 "分析这张卫星图像中的农业灾害" 并附带图片,模型可直接生成灾害类型、影响范围及应对建议。
3.2 训练数据与上下文处理
从数据规模角度来看,LLaMA 3的训练数据量达15万亿tokens,非英文语料占比28%,代码占比12%;而LLaMA 4的训练数据总量则达到了50万亿tokens,非英文语料占比 35%,代码数据占比15%,覆盖100 +语言,显著提升了多语言任务稳定性。
从上下文窗口来看,LLaMA 4的Scout 版本支持1000万 token输入,大大刷新了开源模型长文本处理纪录,适用于法律卷宗分析、工业日志监控等场景。
3.3 推理效率与部署适配
与GPT和Gemini等封闭式API模型不同,LLaMA系列从设计之初就强调"可自定义"和"低资源环境适配"。用户可以自由下载模型权重,通过LoRA、QLoRA等方式进行高效微调,尤其适合中小型开发团队的快速部署。
技术优化上,通过引入FlashAttention 3与SwiGLU-X 激活函数,LLaMA 4的推理速度较前代不断提升;硬件兼容方面, Scout版本在单卡 H100(80GB 显存)环境下可运行,支持实时代码审查,Maverick版本则需多卡H100服务器,支持视频内容理解等较为复杂的任务;微调支持上,LLaMA 4兼容 QLoRA 4-bit 量化技术,支持客户在消费级GPU上完成领域微调;兼容框架上,LLaMA 4已全面支持Hugging Face Transformers、vLLM、LangChain、LlamaIndex 等主流工具,适用于问答系统、检索增强生成、代码补全、教育助理等多种应用。
表4 微调成本与部署适配能力对比
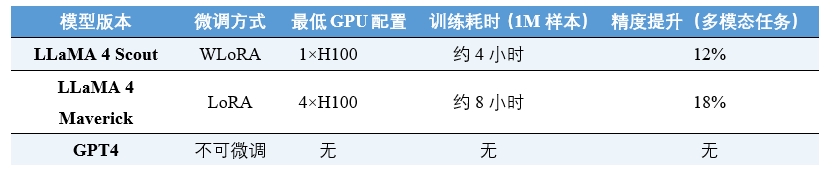
(数据来源:Meta AI Technical Report)
Part 4 开放生态与社区影响
与闭源模型相比,LLaMA系列的核心优势在于它所激活的开源生态力量。无论是模型调用工具链的适配程度,还是社区对其进行二次开发的广度,LLaMA 都已成为开源大模型发展的重要基石之一。
4.1 开放平台广泛支持
LLaMA 4发布后,主流开源社区便迅速做出响应:Hugging Face在48小时内上线了全版本权重,推出多模态Transformers接口,支持图像--文本联合编码;AWS SageMaker:同步集成了LLaMA 4,提供Serverless推理服务,用户可一键部署多模态模型;LangChain+Multimodal则新增了视觉插件,支持构建 "图像上传--分析--报告生成" 全流程应用。这意味着开发者可以在短时间内,将LLaMA 4集成进已有的AI产品之中,而不必等待平台厂商的定制版本更新。
表5 LLaMa 4在开放平台的集成情况
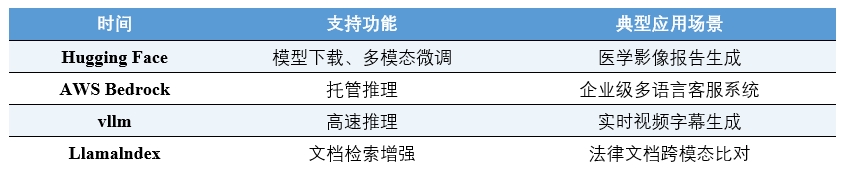
(数据来源:各平台LLaMA 4集成公告等)
4.2 与其他开源模型的差异化定位
目前,主流的开源大模型除LLaMA外,还包括Mistral系列、Mixtral MoE、Falcon 180B、Command-R+等模型。它们各有不同的优化策略和使用场景。例如,Mistral强调轻量高效,适合边缘部署;Mixtral借助MoE架构,提升计算利用率;Command-R+专注于多轮指令跟随。
LLaMA则倾向于做"通用能力+广泛适配"的模型底座,追求稳定、完整、透明的数据路径与结构规范,便于集成与改造。LLaMA并不试图与其他开源模型进行"性能正面对抗",而是通过架构稳定性与部署灵活性,鼓励社区将其接入多种平台和产品,从而赢得大量工具开发者和系统集成团队的认可。
表6 LLaMA4与其他开源模型的差异化定位
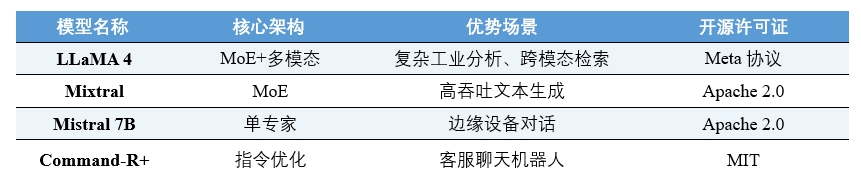
(数据来源:各模型官方资料介绍)
4.3 社区衍生模型生态
LLaMA 4的开源特性促成了丰富的垂直领域生态。例如:1)MedLLaMA-Vision:基于Maverick微调,支持医学影像诊断与文本报告生成,已用于临床试验数据标注;2)CodeLLaMA-MoE:针对编程任务优化,支持代码--流程图跨模态生成,提升软件开发效率30%;3)EduLLaMA:多语言教育助手,支持图文教材解析与语音互动,覆盖K12到高等教育场景。
Meta也鼓励社区基于原始权重进行定向训练,在官方文档中提供了微调范式与LoRA配置参考。这一"模型+社群"的结构,极大提高了LLaMA系统的可迁移性,也构建出一套适合不同组织自定义演化的模型生态结构。例如,基于LLaMA 3微调的法律问答模型LegisLLaMA,已被超过20家的司法机构采用。截至2025年5月,Hugging Face已收录超800个基于LLaMA 4的微调模型,形成了从通用基础模型到垂直应用的完整生态链。
Part 5 未来展望
LLaMA并不是最强大的语言模型,但它可能是当前"最具建设意义"的开源模型之一。在闭源模型主导的 AI生态中,Meta通过开放权重、公开架构和支持微调,为开发者提供了可自主掌控的基础设施级能力。LLaMA 4的发布标志着开源大模型进入 "多模态+高效能" 的新纪元。未来,随着MoE架构的成熟与训练数据的扩容,LLaMA系列或将进一步突破性能边界,推动AI技术向更普惠、更多元的方向发展。
正如Meta AI 负责人所言:"LLaMA不是终点,而是下一代可组合式AI的起点。" 通过开源生态的协同创新,Meta正试图构建一个由开发者主导、适配多元场景的智能模型网络,为全球AI产业提供 "模块化、可进化" 的底层支撑。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号